NHK番組のジャンル予測
出版日: 2021年9月20日

顧客フィードバック、ユーザーレビュー、またはメールの内容など、日本語のテキストがあり、そのデータから洞察を抽出したいですか? 以下に紹介するモデルは、日本語テキストとともに使用する場合、マルチクラス分類において素晴らしい仕事をします。 このモデルは日本語を理解し、離反率の予測、消費者セグメンテーション、顧客センチメント分析など、多くのアプリケーション領域で潜在的に使用できます。
P.S.: このモデルは、2行を変更することで他の言語に簡単に適応できます。
データ
我々はNHK(日本放送協会)の番組情報をデータソースとして使用します。 NHKの番組スケジュールAPIを介して、日本全国のテレビ、ラジオ、インターネットラジオで次の7日間に放送予定のすべての番組の[タイトル、サブタイトル、内容、ジャンル]を取得できます。
問題の設定
番組のタイトル、サブタイトル、内容を使用して、そのジャンルを予測しようとします。 プログラムには以下のように複数のジャンルがある場合があります:
- タイトル: あさイチ「体験者に聞く 水害から家族・暮らしを守るには?」
- ジャンル: 1) 情報/ワイドショー, 2) ドキュメンタリー/教養
上記の場合、この番組のジャンルを情報/ワイドショーと仮定します
このモデルの改善点は、1つの番組に複数のジャンルを予測できるようにすることであり、これにより、この問題はマルチクラスマルチターゲットの問題となります。
探索的データ分析(EDA)
2021/8/30から2021/9/24の間に放映された(または放映予定の)10,321件のユニークな番組に関する情報を収集しました。 10,321件の番組の13のジャンル(ラベル)の分布は以下の通りです:
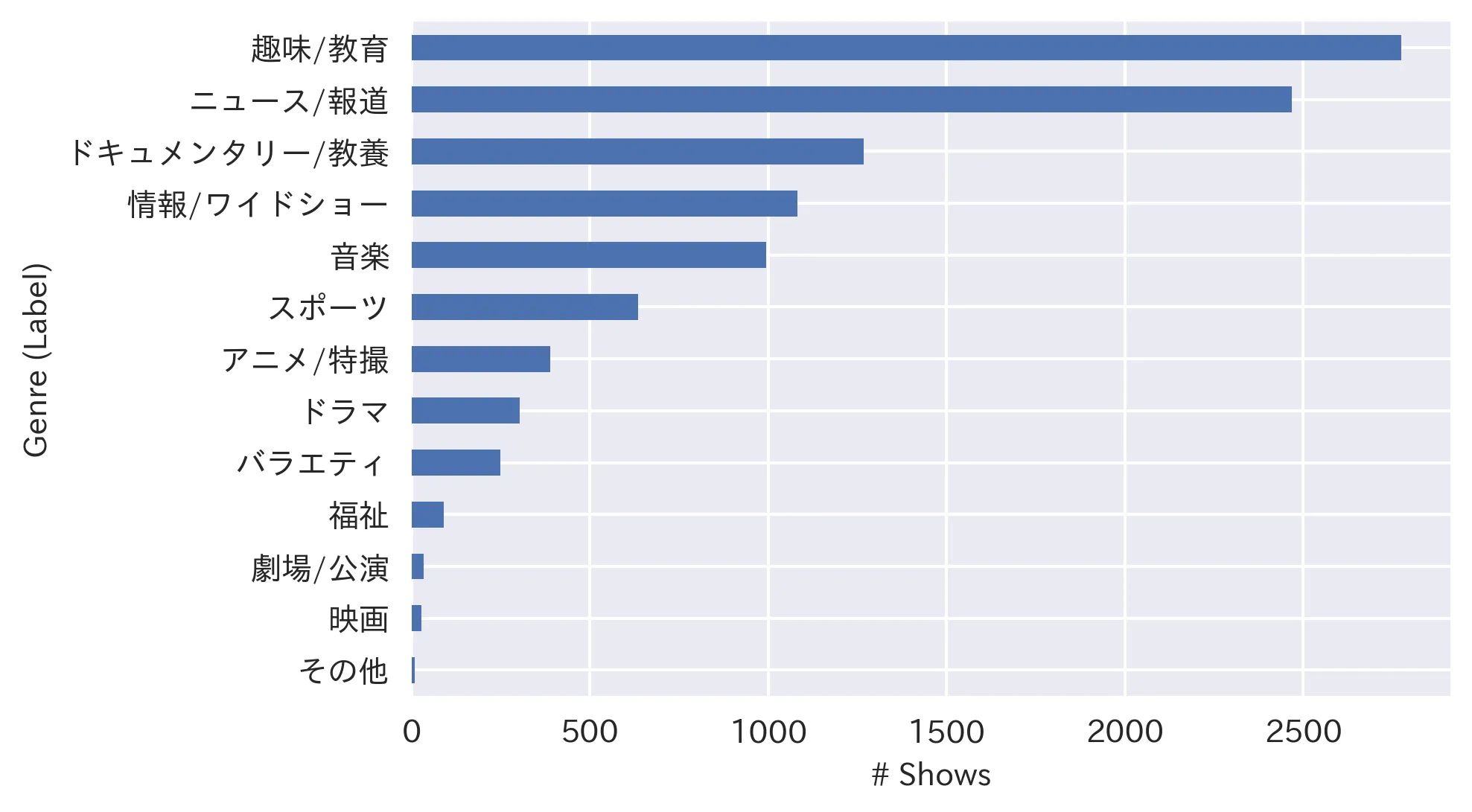
データが非常に不均衡であることがわかるので、データをトレーニングとテストに分割する際には、「層別化」しています(つまり、テストデータのラベル分布を全データセットと同じに保持し、不均衡なデータセットに適した精度メトリックとして重み付きF1スコアを使用します)。
データ処理
データをトレーニング(80%)およびテスト(20%)データセットに分割します。 トレーニングデータセットでモデルをトレーニングし、テストデータセットの精度を10のエポックで追跡します(エポック:モデルが全体のトレーニングデータセットを通過するステップ)。 最高の精度を生み出すエポックが最終モデルとして使用され、そのモデルからの結果がモデルの精度と見なされます。
モデル
モデルへの入力は、各番組の「タイトル」、「サブタイトル」、「内容」の連結です。 一部の番組には上記のすべての情報がない場合もありますが、少なくとも1つのフィールドがあれば大丈夫です(タイトルは常に利用可能です)
モデルの出力は、13の利用可能なジャンルに対する確率分布であり、最も高い確率のジャンルをモデルの出力として取り、真の値と比較します。
BERT
このモデルのトレーニングには、BERTの事前トレーニング済みモデルの1つを使用し、問題に合わせて微調整します。 BERTの動作を確認するには、この記事 を参照してください。 事前トレーニング済みモデルを取得するためのインターフェイスを提供する🤗 Hugging Faceライブラリを使用します。 取得する事前トレーニング済みモデルは、 bert-base-japanese-v2 です。これは東北大学の研究者がWikipediaから30Mの日本語文章を使用してトレーニングしたものです。 ファインチューニングには、 BertForSequenceClassificationモデルを使用します。これは基本的にはシーケンス分類問題です。
結果
BERTは重いモデルであり、CPUではかなり長い時間がかかるため、Google Colabでモデルをトレーニングします。 トレーニングデータは、学習を加速し、RAMオーバーフローを防ぐためにサイズ32のバッチでモデルに供給されます。 モデルは10のエポックでトレーニングされます:これらの10のエポックでの損失と精度メトリックは以下の通りです:
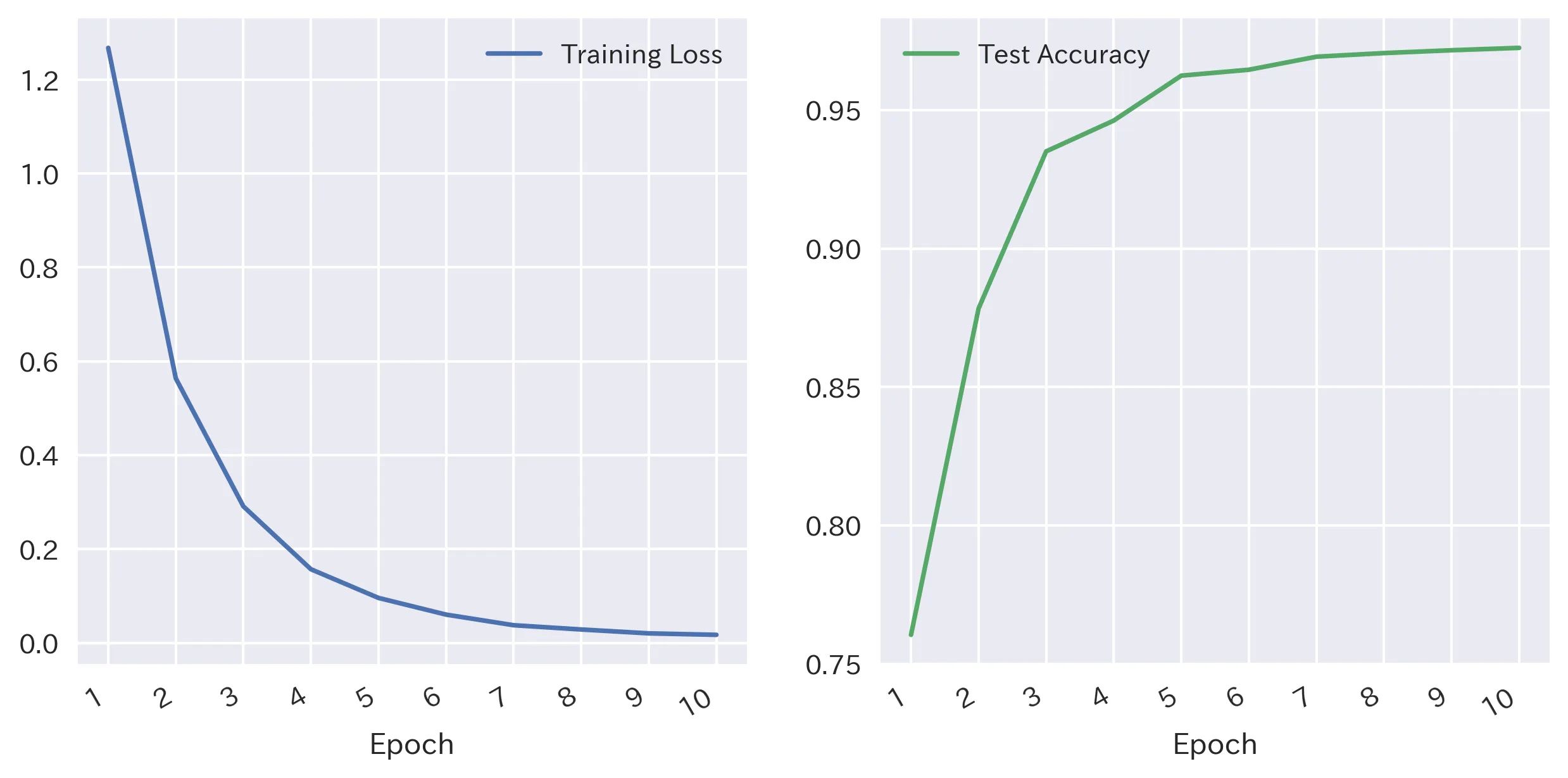
10エポックは十分のようです。トレーニング損失とテスト精度はその後平坦になります。各ラベルの予測のパフォーマンスを見てみましょう:
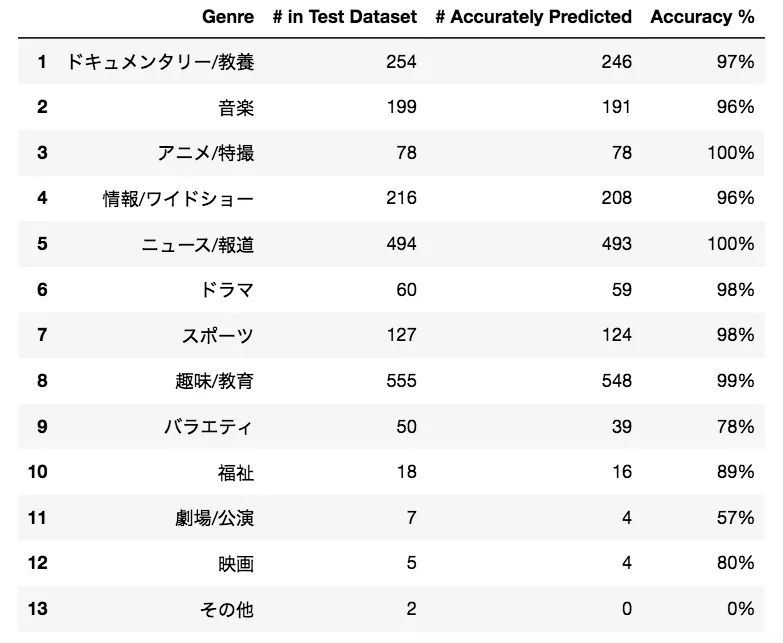
最後に、混同行列を確認しましょう:
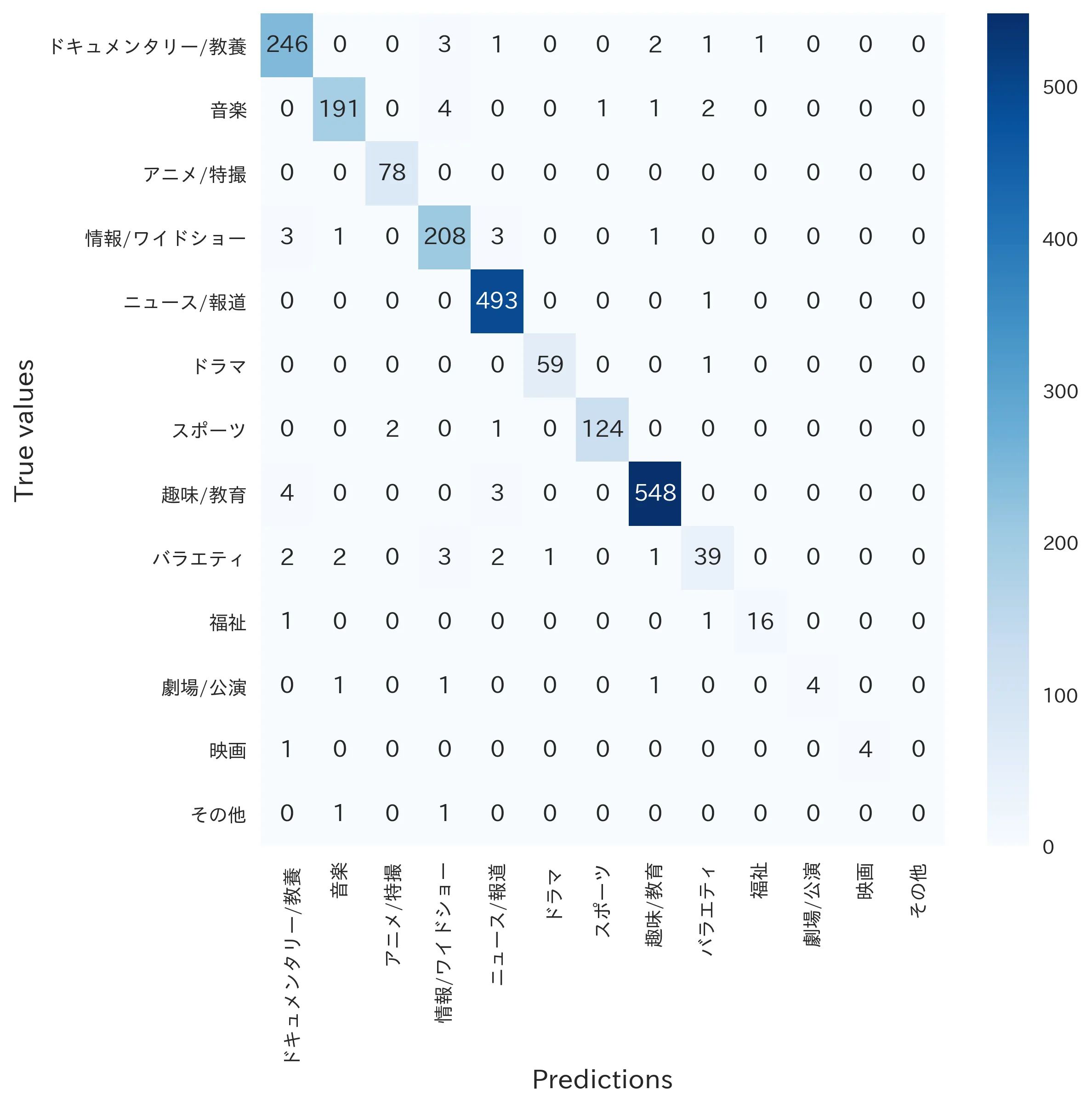
かなり良さそうですね?
結論
この記事では、BERT事前トレーニング済みモデルを使用し、日本のテレビ番組やラジオ番組を複数のジャンルに分類するためのマルチクラステキスト分類を97%の精度で行いました。
私が観察した傾向の1つは、トレーニングデータが大きくなるにつれて、精度も向上していることです。 2週間のデータでは94%の精度が得られましたが、1か月のデータでは97%の精度が得られました。 このモデルは、より多くのデータが収集されるにつれてほぼ完璧な予測精度を達成できると予想しています。 このモデルの次のステップは、1つの番組に複数のジャンルを予測することであり、これにより、この問題はマルチクラスマルチラベルの問題となります。
ご質問やフィードバックがある場合は、danyelkoca@gmail.comまでお知らせください。以下のソースコードとデータセットを見つけることができます:
ハッピーハッキング!
この作品は英語からChatGPTによって翻訳されました。不明な点がある場合は、お問い合わせページからご連絡ください。
コメントを残す
コメント
現在コメントがありません。
その他の作品

2024/06/03
Kango: 漢字当てゲーム

2024/07/24
Lingo: 単語当てゲーム

2024/04/29
Druggio

2024/01/28
テトリス

2022/04/29
移動物体検出

2022/03/15
大気温の予測

2022/02/09
機械学習を用いて東京の賃貸価格予測
2021/12/01
日本薬品データベース

2021/09/01
移動需要の予測