日本薬品データベース
出版日: 2021年12月1日
前職では、日本の薬に関する多くの机上調査を行っていました。たとえば、新しいプロジェクトを開始する際には、その薬のタイプ、薬が指示されている疾患(適応症)、作用機序、同じ分野の他の薬、価格などを見つけるのが一般的な手続きでした。
しかし、複数の適応症を持つ薬を扱う場合、これはかなり面倒になります。たとえば、一部のがん治療薬は10以上の異なるがんの種類を治療します。そのため、各適応症に対する競合他社の概要と、それらの競合他社の各薬の価格と製造元を見つけることが悪夢になります。
そのため、私は日本の薬のデータベースを作成することにしました。これらの薬のそれぞれに収集する必要がある主な情報は次のとおりです:
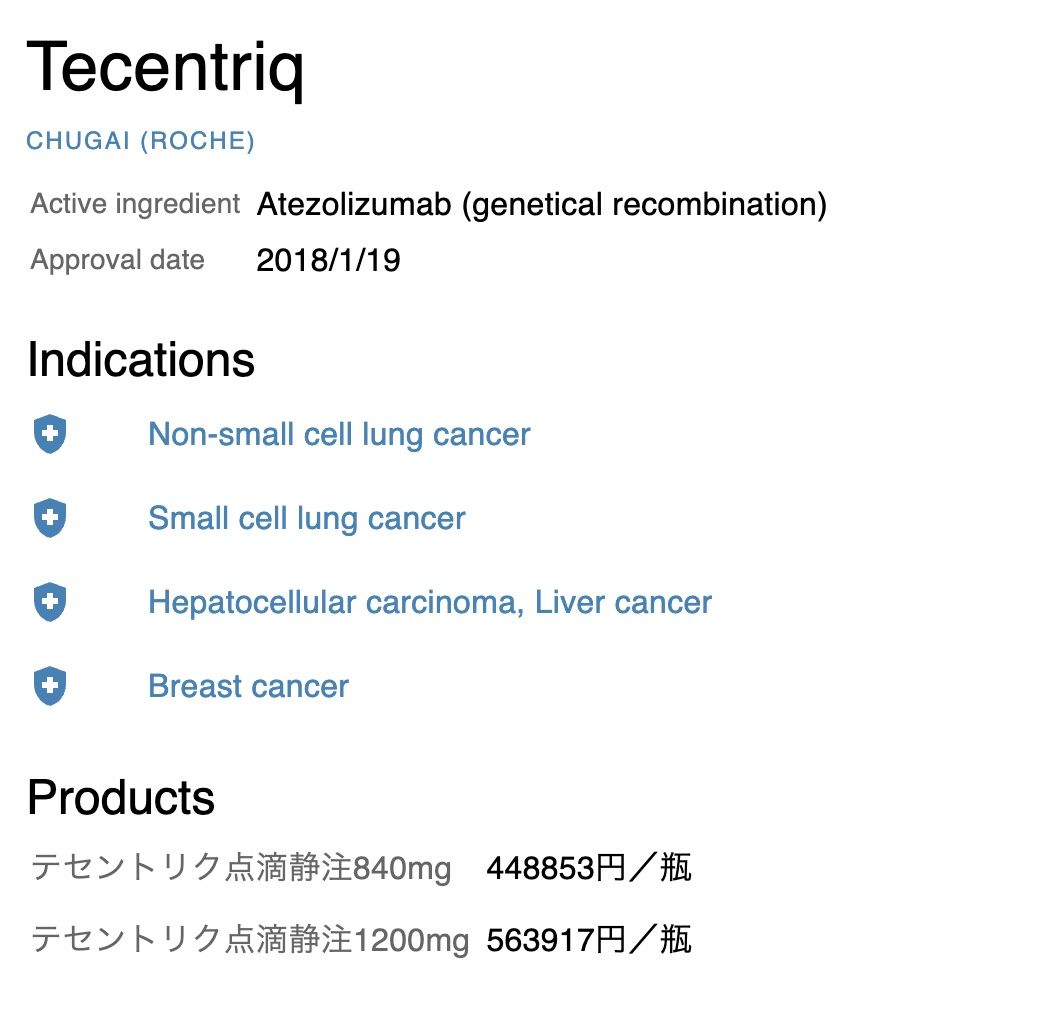
- 薬の名前
- 製造元
- 有効成分
- 承認日
- 適応症
- 製品(ml / 価格)
そして、アイデアは、適応症をクリックすると、その疾患に指示されているすべての薬を表示できるようにすることです。これにより、特定の薬の特定の適応症の競合他社を見つけるのが非常に簡単になります。
さらに、ある製造元のすべての薬(例:ファイザー)を見ることができ、その全ポートフォリオを表示できます。
最後に、薬のすべての適応症とその薬の製品を一覧で表示できます。なぜなら、一部の薬にはいくつかの治療法(錠剤、ワクチン、異なる投与量など)があるからです。
データ収集
データは主にKEGG: 京都遺伝子およびゲノム百科事典から収集されています。彼らが必要なすべての情報を編纂しているため、彼らが重要な仕事をしています。私たちがやるべきことは、その情報を取得し、適応症と製造元ごとにそれを再構成し、ユーザーが簡単に検索できるようにすることです。
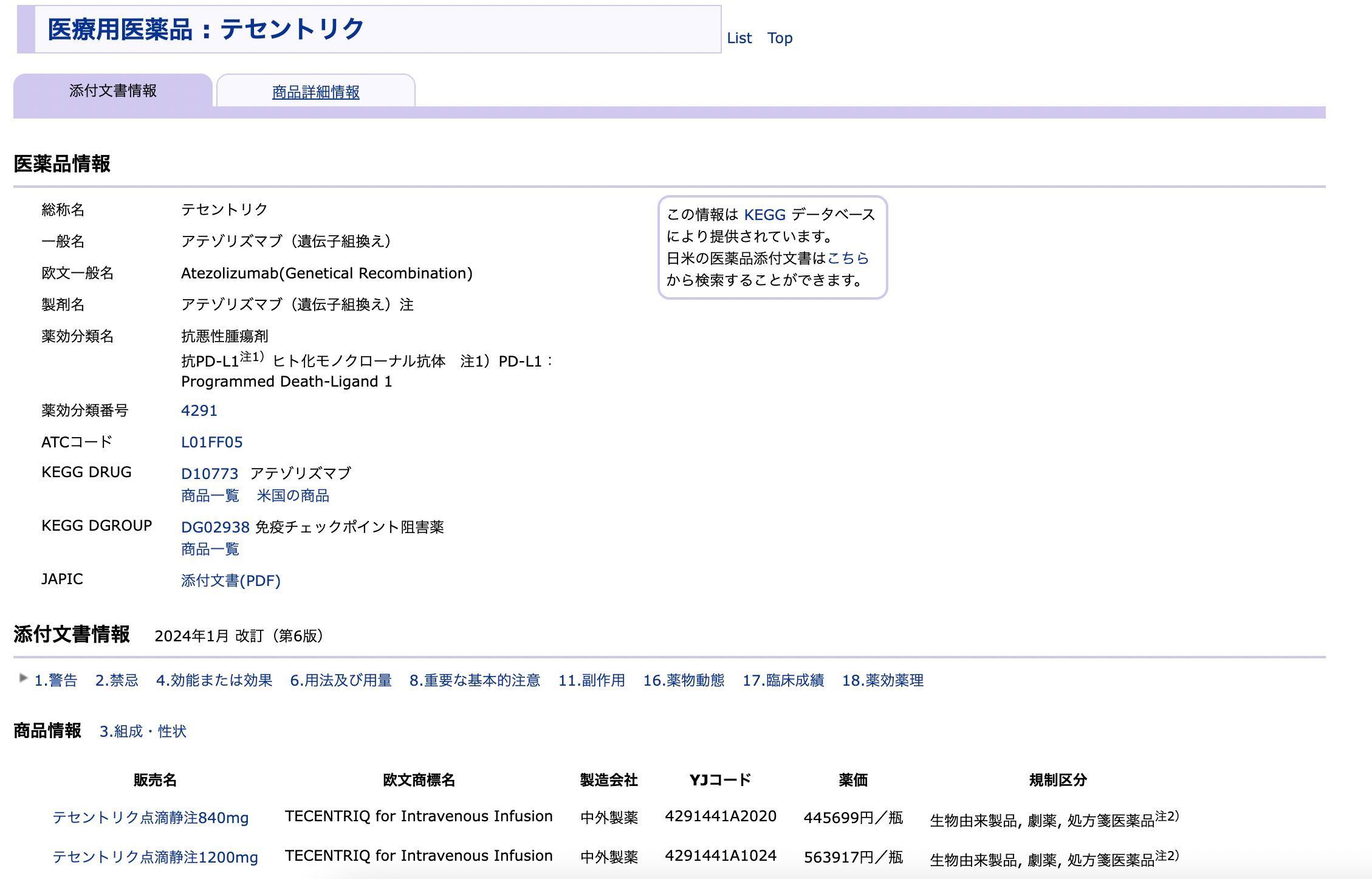
データ処理
KEGGからデータを収集した後、いくつかの処理を行う必要があります。これには、古い製造元を削除し、最新バージョンに更新し、データを英語と日本語に整理し、会社と疾患をIDで表現し、正確な検索を行うための準備を行う必要があります。整理されたデータは以下のようになります:
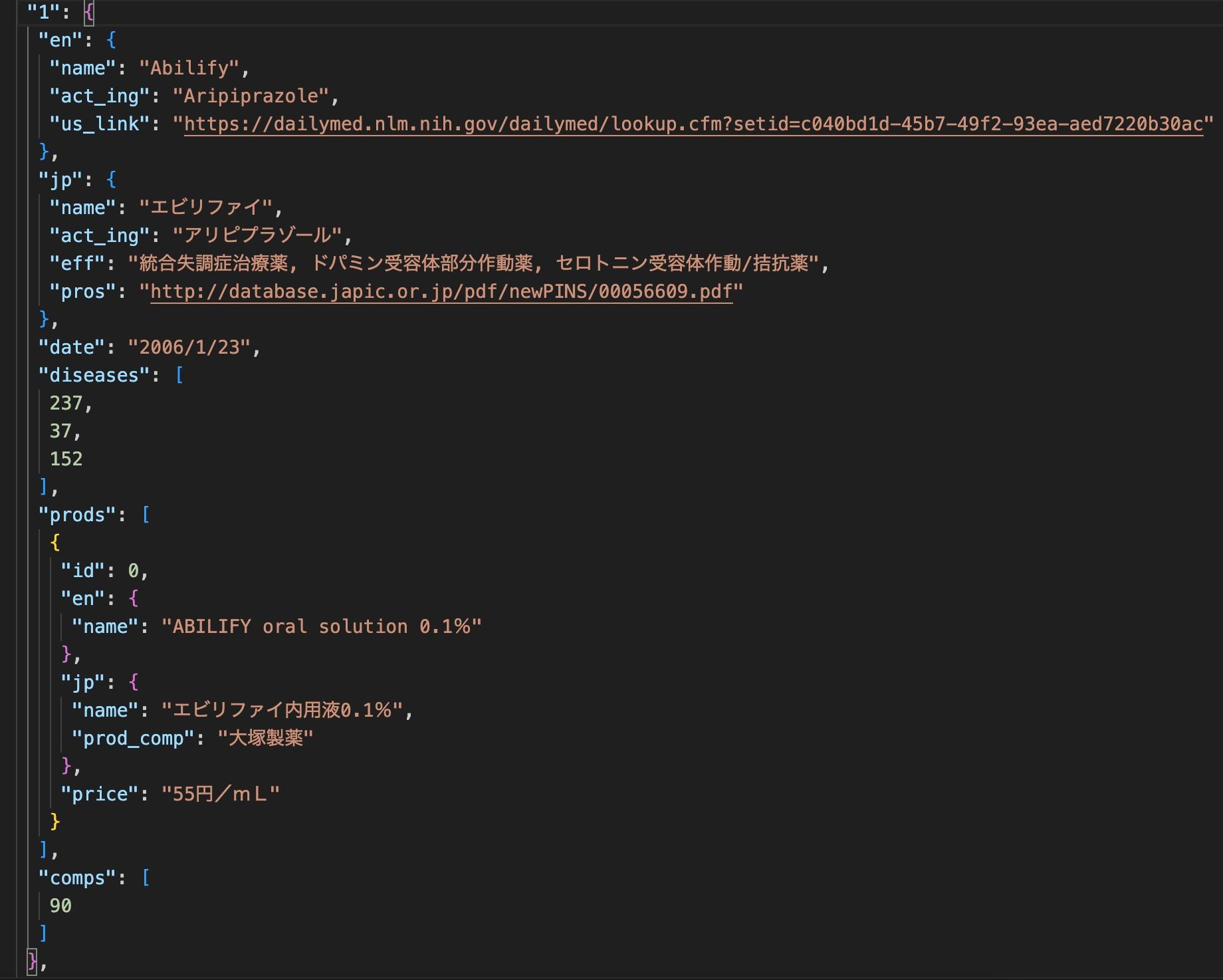
上記のデータ構造は各薬のために作成され、最終的に日本で承認された薬のデータベースができます。
データの提供
このプロジェクトの最も難しい部分(ほとんどのデータサイエンスプロジェクトと同様)は、データを整形することです。整理されたデータがあると、今度はユーザーにこのデータを提供するためのフロントエンド/バックエンドを構築する必要があります。
このため、私たちはNEXT.JSを使用して、ユーザーが薬、競合他社、適応症を検索し、結果を表示できるインターフェースを作成するための単一ページアプリを構築します:
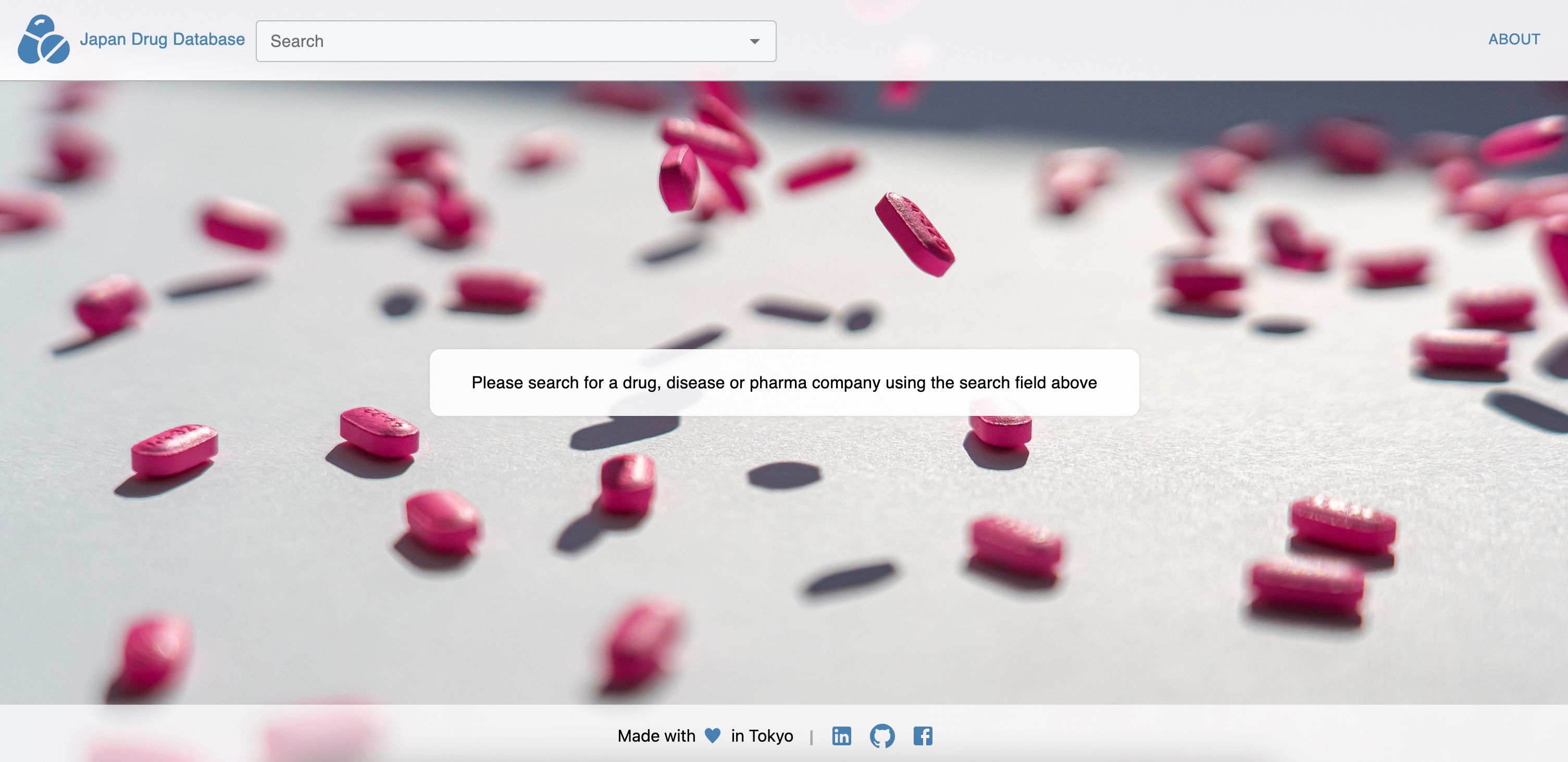
まとめ
この記事では、日本で承認された薬のデータベースを作成し、ユーザーがこのデータを探索できるインターフェースを構築する方法を見ました。
私はこのプロジェクトを日本薬データベースと呼んでいます。検索エンジンへのリンクはこちらです。
データやインターフェースの構築に関する質問があれば、お知らせください。
Happy hacking!
この作品は英語からChatGPTによって翻訳されました。不明な点がある場合は、お問い合わせページからご連絡ください。
コメントを残す
コメント
Random
7ヶ月前1
その他の作品

2024/06/03
Kango: 漢字当てゲーム

2024/07/24
Lingo: 単語当てゲーム

2024/04/29
Druggio

2024/01/28
テトリス

2022/04/29
移動物体検出

2022/03/15
大気温の予測

2022/02/09
機械学習を用いて東京の賃貸価格予測

2021/09/20
NHK番組のジャンル予測

2021/09/01
移動需要の予測