Japonca Yazi Siniflandirmasi
Yayın: 20 Eylül 2021

Müşteri geri bildirimi, kullanıcı yorumları veya posta içerikleri gibi Japonca metinleriniz var mı ve elinizdeki verilerden içgörüler çıkarmak mı istiyorsunuz? Aşağıda tanıtılan model, Japonca metinlerle kullanıldığında çok sınıflı sınıflandırmada harika bir iş çıkarıyor. Model, Japonca dili iyi anlıyor ve müşteri kaybı tahmini, tüketici segmentasyonu, müşteri duygusal analizi gibi birçok alanda potansiyel olarak kullanılabilir.
Not: Bu model, 2 satırı değiştirerek diğer dillere kolayca adapte edilebilir.
Veri
NHK (Japonya Yayın Kurumu)'nun program bilgilerini veri kaynağı olarak kullanacağız. NHK'nın Gösteri Programı API'si aracılığıyla, Japonya genelinde TV, Radyo ve İnternet Radyo için gelecek 7 gün boyunca planlanmış tüm gösteriler için [başlık, alt başlık, içerik, tür] bilgilerini alabilirsiniz.
Problemin Tanımı
Bir gösterinin başlığı, alt başlığı ve içeriği kullanarak türünü tahmin etmeye çalışacağız. Bir programın şu şekilde birden fazla türü olabilir:
- Başlık: あさイチ「体験者に聞く 水害から家族・暮らしを守るには?」
- Tür: 1) 情報/ワイドショー, 2) ドキュメンタリー/教養
Yukarıdaki durumda, bu gösterinin türünü 情報/ワイドショー (Bilgi/Geniş gösteri) olarak kabul edeceğiz
Bu modelin bir iyileştirmesi, her bir gösteri için birden fazla türü tahmin edebilen model olacak, bu da bu sorunu çok sınıflı çok hedefli bir problem haline getirecektir.
Keşfedici Veri Analizi (EDA)
2021/8/30 ile 2021/9/24 arasında yayınlanan (veya yayınlanacak) 10.321 benzersiz gösteri hakkında bilgi topladım. 10.321 gösteri arasında 13 türün (etiketin) dağılımı aşağıda verilmiştir:
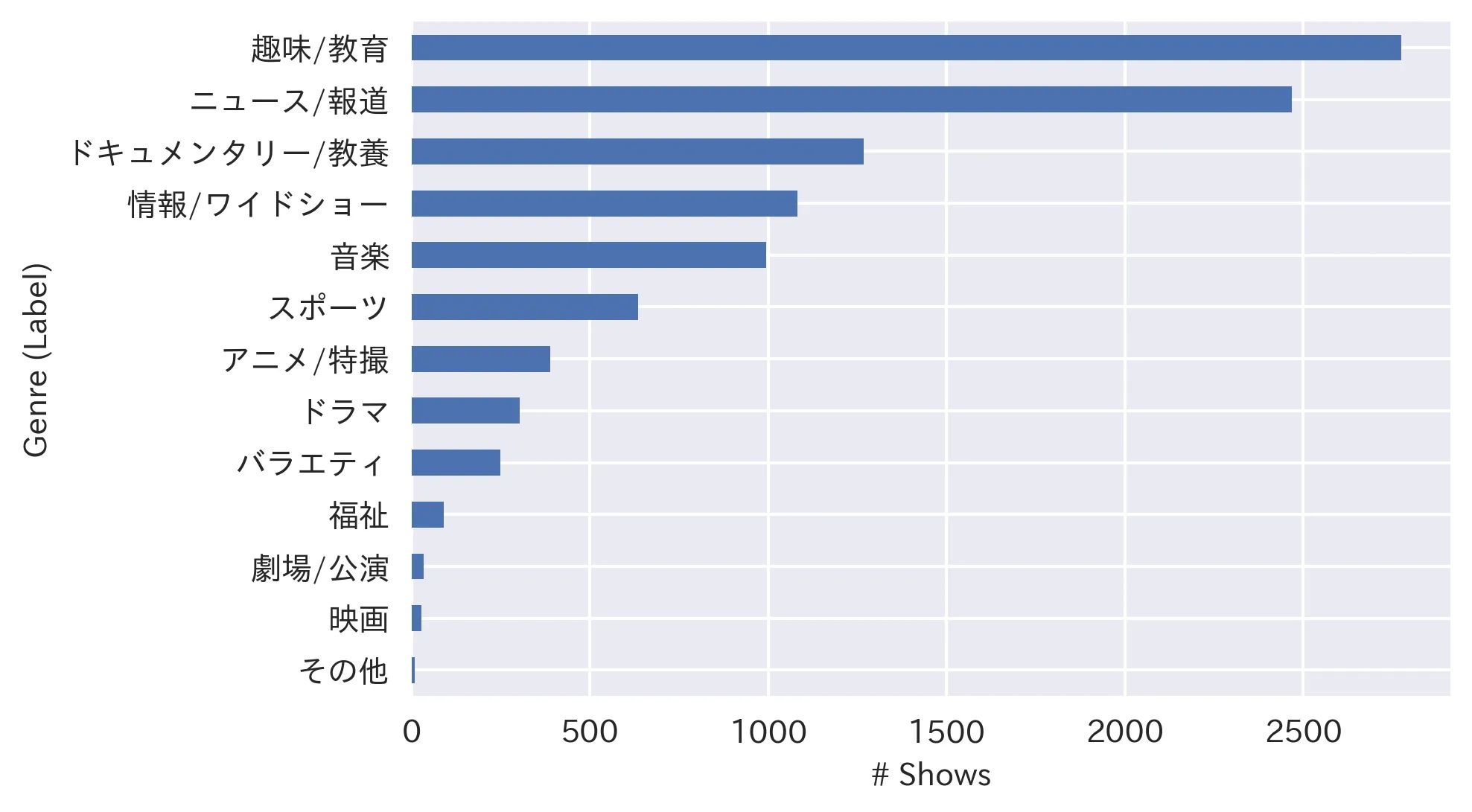
Gördüğünüz gibi, veri oldukça dengesizdir, bu nedenle veriyi eğitim ve test olarak bölerken verimizi "tabakalı" hale getireceğiz (yani: test verilerinde etiket dağılımını bütün veri seti ile aynı tutarak), ve dengesiz veri kümeleri için uygun olan Ağırlıklı F1 skorunu doğruluk metriği olarak kullanacağız.
Veri İşleme
Veriyi eğitim (%80) ve test (%20) veri setlerine böleceğiz. Modeli eğitim veri setinde eğiteceğiz ve test veri setinin doğruluğunu 10 epoch boyunca takip edeceğiz (epoch: modelin tüm eğitim veri setini geçtiği adım). En yüksek doğruluğu üreten epoch, son model olarak kullanılacak ve bu modelden elde edilen sonuçlar model doğruluğu olarak kabul edilecektir.
Model
Modelimize giriş, her bir gösterinin “Başlık”, “Alt Başlık” ve “İçeriğinin birleştirilmesi olacak. Bazı gösterilerde yukarıdaki tüm bilgiler olmayabilir, ancak en azından 1 alanın olması yeterlidir (Başlık her zaman mevcuttur)
Modelin çıkışı, 13 mevcut tür için bir olasılık dağılımı olacak ve en yüksek olasılığa sahip türü model çıkışı olarak alacak ve gerçek değerle karşılaştıracağız.
BERT
Bu modeli eğitmek için, BERT'in önceden eğitilmiş modellerinden birini kullanacağız ve onu sorunumuza göre ayarlayacağız. BERT'in nasıl çalıştığını görmek için bu makaleye bakın. Önceden eğitilmiş modeli almak için bir arayüz sağlayan 🤗 Hugging Face kütüphanesini kullanacağız. Alacağımız önceden eğitilmiş model bert-base-japanese-v2 Tohoku Üniversitesi'ndeki araştırmacılar tarafından Wikipedia'dan 30 milyon Japonca cümle kullanılarak eğitildi. Yeniden ayarlamak için, esasen bir dizi sınıflandırma problemi olduğundan BertForSequenceClassification modelini kullanacağız.
Sonuçlar
Modeli Google Colab'da bir GPU çalışma zamanı ortamında eğiteceğiz çünkü BERT ağır bir modeldir ve CPU'da önemli ölçüde daha uzun süre alır. Eğitim verileri, öğrenmeyi hızlandırmak ve RAM taşmasını önlemek için boyutu olan 32'lik partiye verilir. Model, 10 epoch boyunca eğitilecek: Bu 10 epoch boyunca kayıp ve doğruluk metrikleri aşağıdaki gibidir:
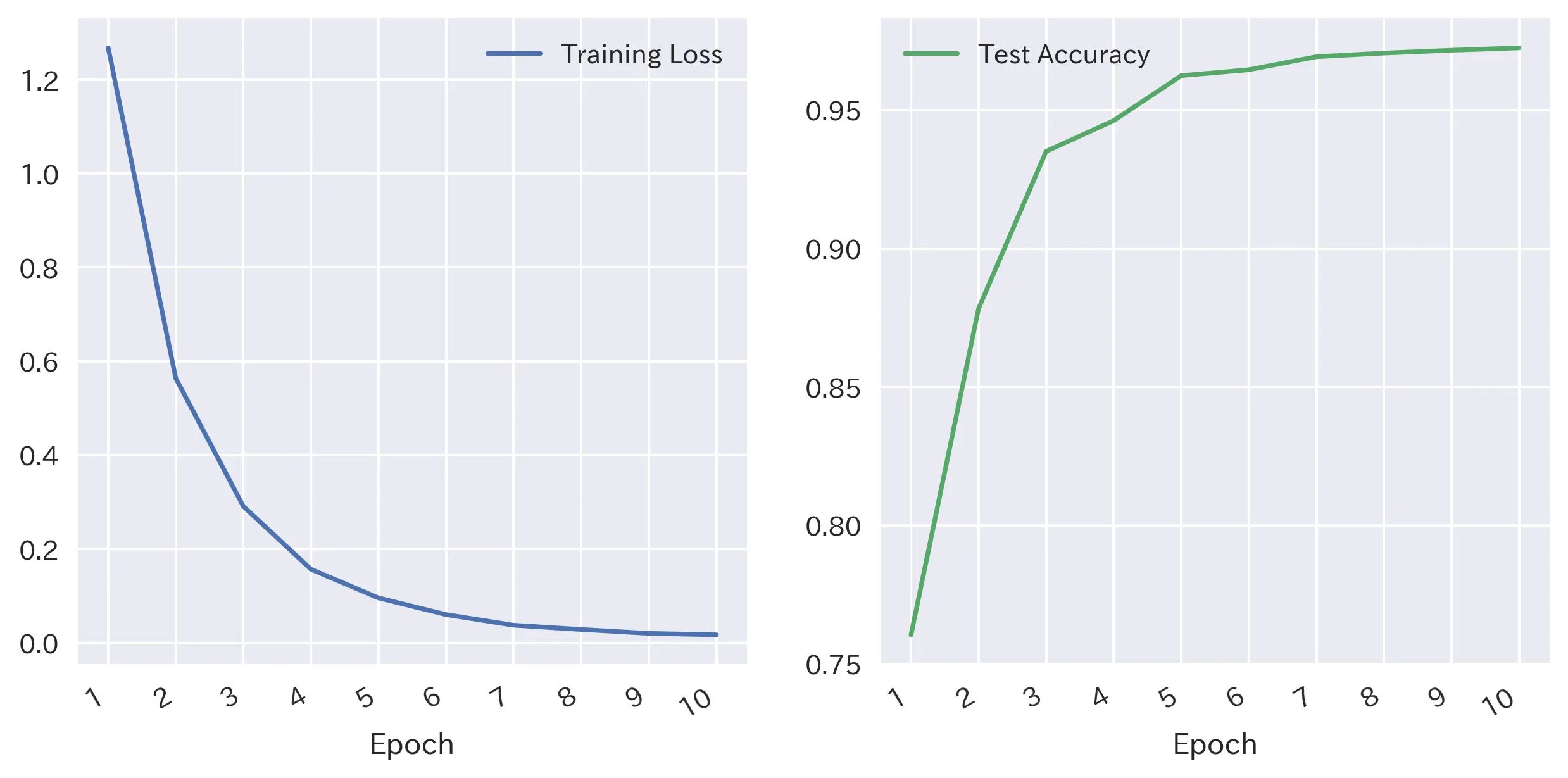
10 epoch'un yeterli olduğu görünüyor çünkü eğitim kaybı ve test doğruluğu bu noktadan sonra düzleşir. Her bir etiketi tahmin ederken nasıl performans gösterdiğimize bakalım:
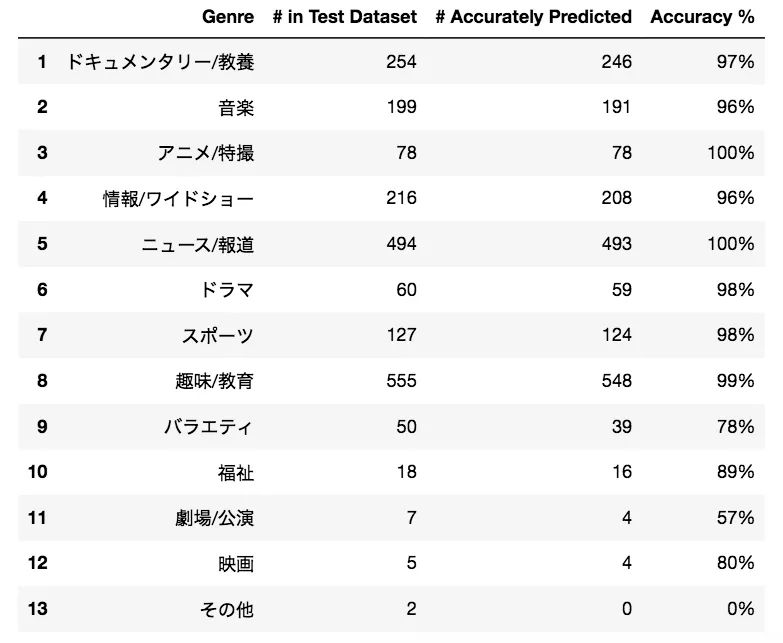
Nihayet, karışıklık matrisini kontrol edelim:
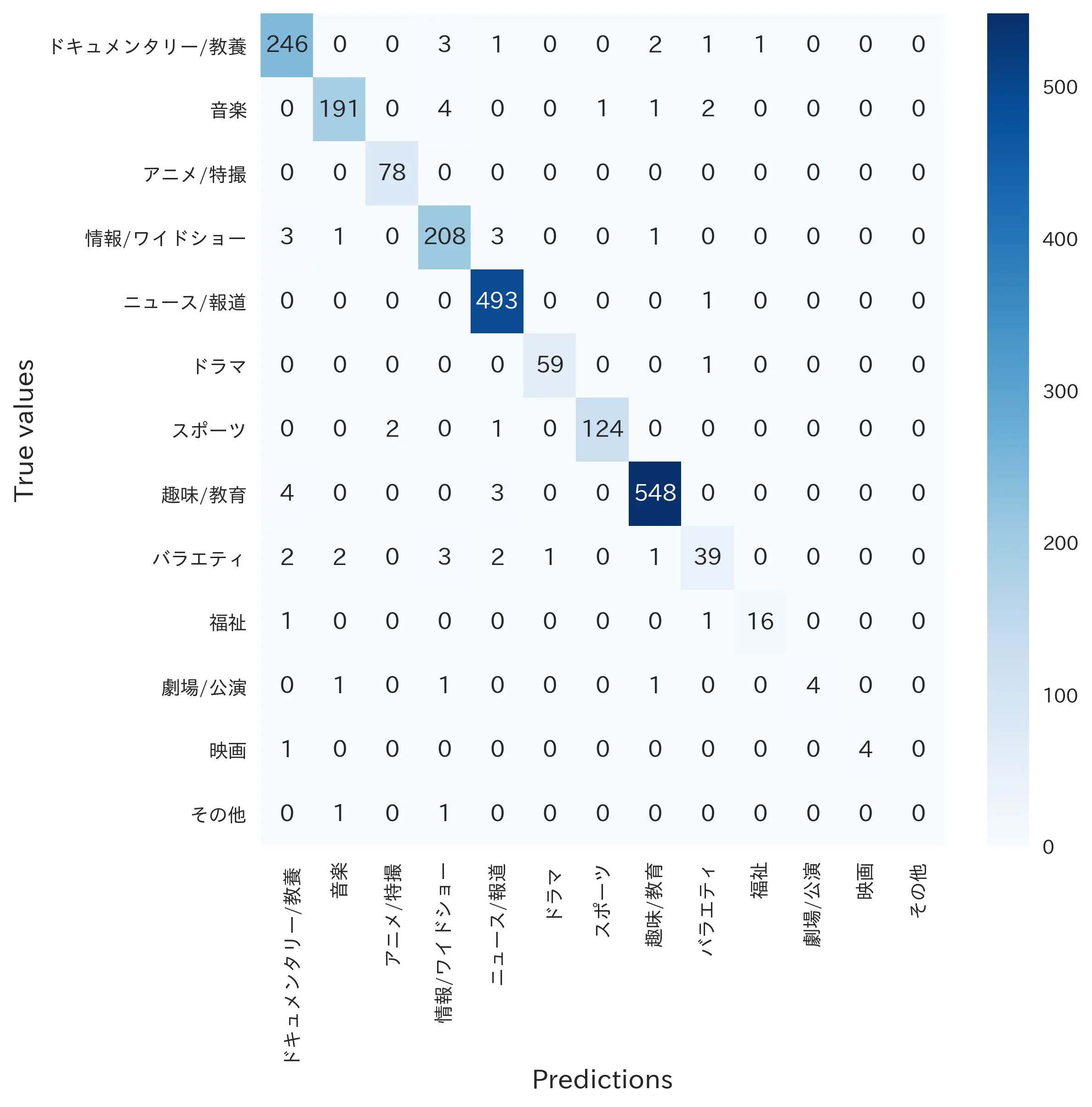
Görünüşe göre oldukça iyi, değil mi?
Sonuç
Bu makalede, Japon TV ve radyo programlarını çoklu türlere sınıflandırmak için BERT önceden eğitilmiş bir model kullandık ve %97 doğruluk elde ettik.
Gözlemlediğim bir trend, eğitim verisi büyüdükçe doğruluğun da artmasıydı. 2 haftalık veri %94 doğruluk sağlarken, 1 aylık veri %97 doğruluk sağlayabiliyordu. Daha fazla veri toplandıkça bu modelin neredeyse mükemmel tahmin doğruluğu elde edebileceğini bekliyorum. Bu modelin bir sonraki adımı, her bir gösteri için birden fazla türü tahmin etmek olacaktır, bu da bu sorunu çok sınıflı çok hedefli bir problem haline getirecektir.
Herhangi bir sorunuz/geri bildiriminiz varsa danyelkoca@gmail.com adresinden bana bildirin. Kaynak kodunu ve veri setini aşağıda bulabilirsiniz:
Mutlu kodlamalar!
Bu iş İngilizce'den LLM ile çevrilmiştir. Herhangi bir belirsizlik durumunda İletişim sayfasından bana ulaşabilirsiniz.
Yorum bırak
Yorumlar
Diğer işlere bak

2025/10/12
Kumamap: Yaban Hayati Takip Sistemi

2025/07/07
YOLO Nesne Algılama

2024/06/03
Kango: Kanji Tahmin Oyunu

2024/07/24
Lingo: Türkiye'nin En Popüler Ücretsiz Online Kelime Oyunu

2024/04/29
Druggio

2024/01/28
Tetris

2022/04/29
Hareket Eden Cisim Tespiti

2022/03/15
Hava Durum Tahmini

2022/02/09
Ev Fiyatlari Tahmini

2021/12/01
Japonya Ilac Veri Bankasi

2021/09/01
Seyahat Talep Tahmini