Japanese Text Classification
Published: September 20, 2021

Do you have some Japanese Text such as customer feedback, user reviews, or mail contents and want to extract insights from the data at hand? The model introduced below does a fantastic job for multiclass classification when used with Japanese text. The model understands the Japanese language well and can be potentially used for many purposes such as churn rate prediction, consumer segmentation, customer sentiment analysis, among many application areas.
P.S.: This model can be easily adapted to other languages by changing 2 lines.
Data
We will use NHK (Japan’s Broadcasting Corporation)’s show information as our data source. Through NHK’s Show Schedule API, you can get [title, subtitle, content, genre] for all the shows scheduled for the next 7 days for TV, Radio, and Internet Radio all across Japan.
Problem statement
Using the title, subtitle, and content of a show, we will try to predict its genre. A program can have multiple genres like below:
- Title: あさイチ「体験者に聞く 水害から家族・暮らしを守るには?」
- Genre: 1) 情報/ワイドショー, 2) ドキュメンタリー/教養
In the above case, we will be assuming this show’s genre is 情報/ワイドショー (Information/ Wide show)
An improvement of this model would be the one which can predict multiple genres per show, which would make this problem a multi-class multi-target problem.
Exploratory Data Analysis (EDA)
I have collected information about 10,321 unique shows that aired (or to be aired) between 2021/8/30 and 2021/9/24. Below is the distribution of all 13 genres (labels) among 10,321 shows:
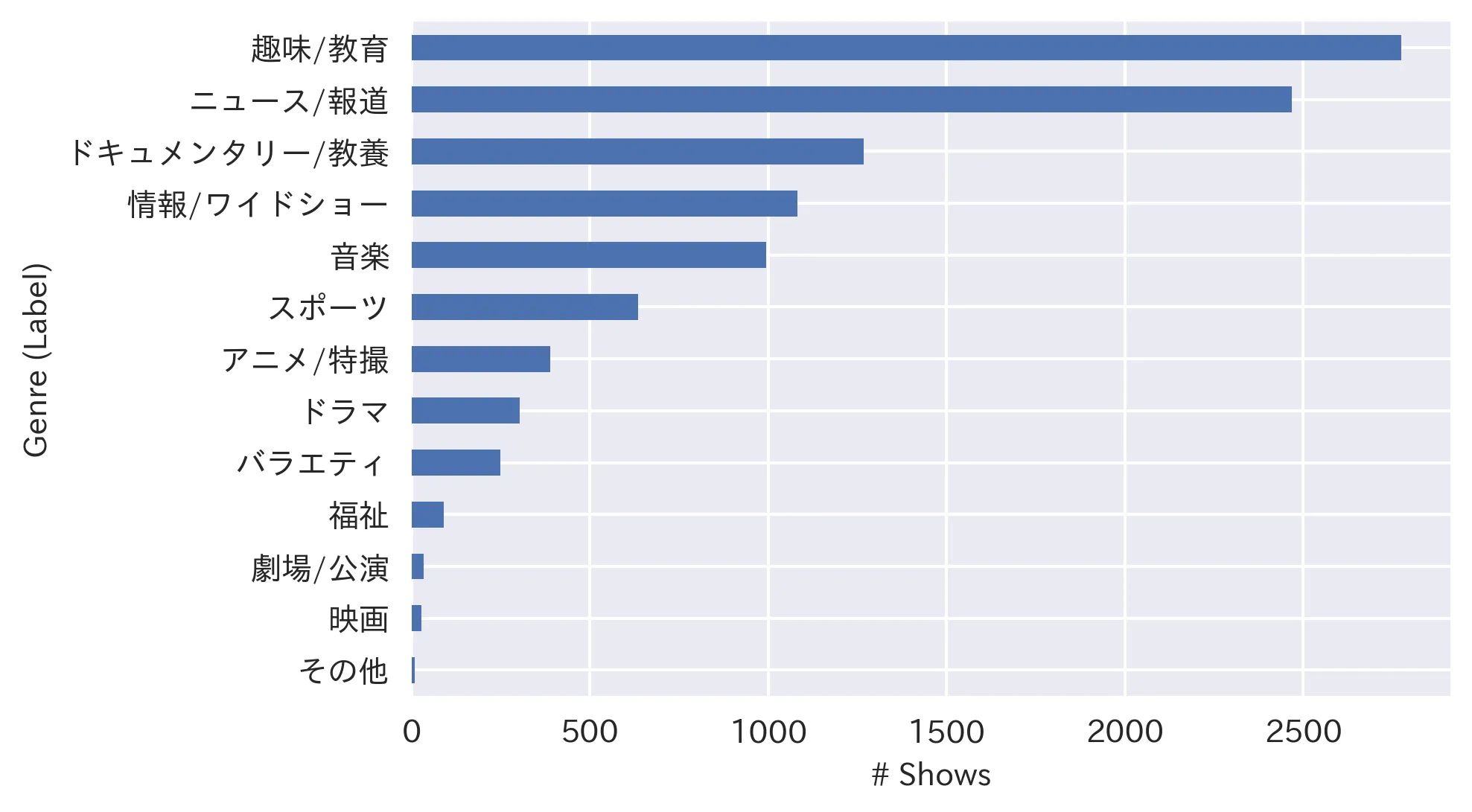
As you can see, data is highly imbalanced, so we will “stratify” our data when dividing it into train and test (i.e.: preserving the label distribution in test data same as the whole dataset), and use Weighted F1 score as accuracy metric which is suited for imbalanced datasets.
Data Processing
We divide the data into training (80%) and test (20%) datasets. We will train the model on the training dataset and track the accuracy of the test dataset across 10 epochs (epoch: 1 step that model goes through whole training dataset). The epoch which produces the highest accuracy will be used as the final model, and results from that model will be considered as model accuracy.
Model
Input to our model will be a concatenation of “Title”, “Subtitle”, and “Content” of each show. Some shows don’t have all of the above information, but that’s fine as long as at least 1 field is there (Title is always available)
The output of the model will be a probability distribution for 13 available genres and we will take the genre with the highest probability as model output and compare it with the true value.
BERT
For training this model, we will use one of BERT’s pre-trained models and fine-tune it for our problem. Check this article to see how BERT works. We will be using 🤗 Hugging Face library which provides an interface for fetching pre-trained BERT models. The pre-trained model we will fetch is bert-base-japanese-v2 which was trained by researchers at Tohoku University using 30M Japanese sentences from Wikipedia. For fine-tuning, we will use the BertForSequenceClassification model as this is essentially a sequence classification problem.
Results
We train the model in Google Colab with a GPU runtime environment as BERT is a heavy model and it takes significantly longer time on CPU. Training data is fed to the model in batches of size 32 to accelerate the learning and prevent RAM overflow. Model is trained over 10 epochs: Below is the loss and accuracy metrics across these 10 epochs:
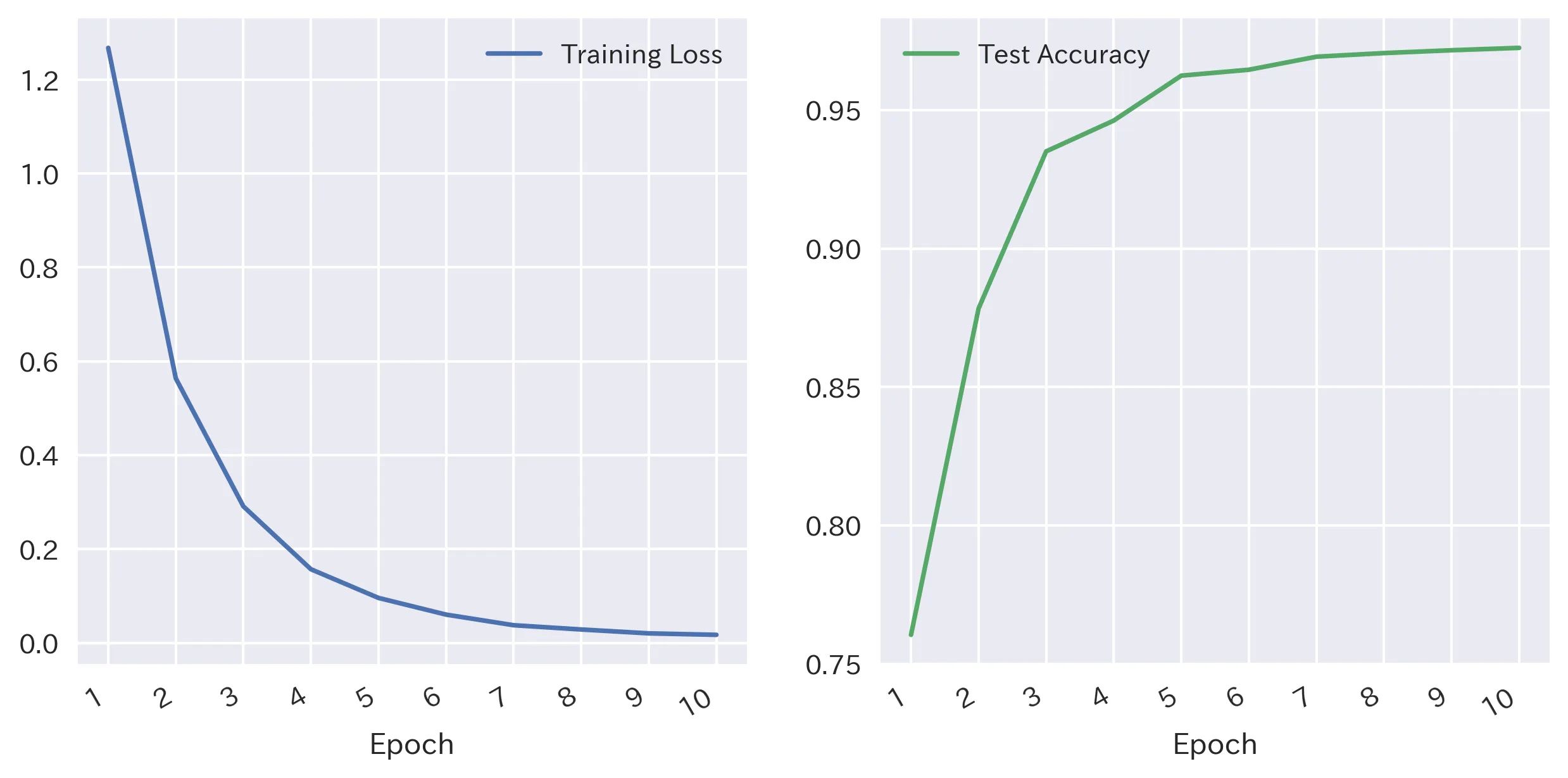
10 epochs seem to be enough as training loss and test accuracy flatline post that point. Let’s see how we performed predicting each label:
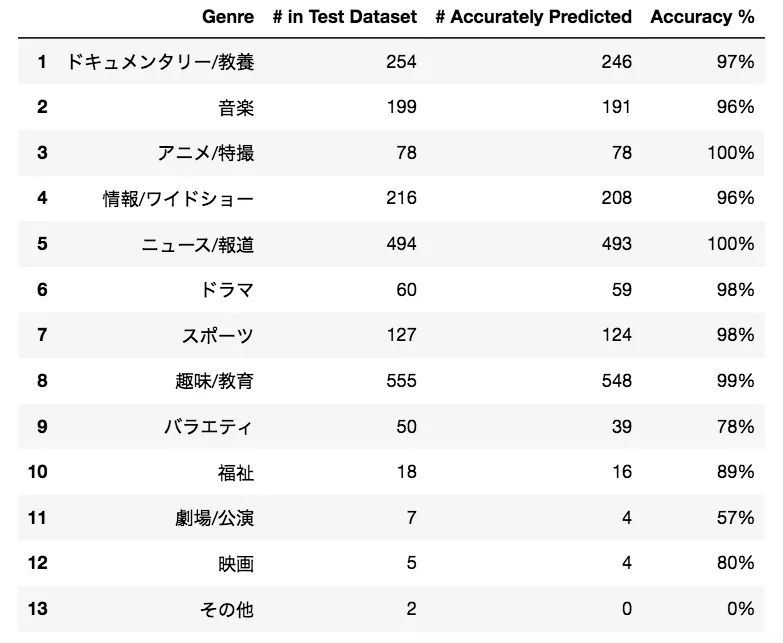
Finally, let’s check the confusion matrix:
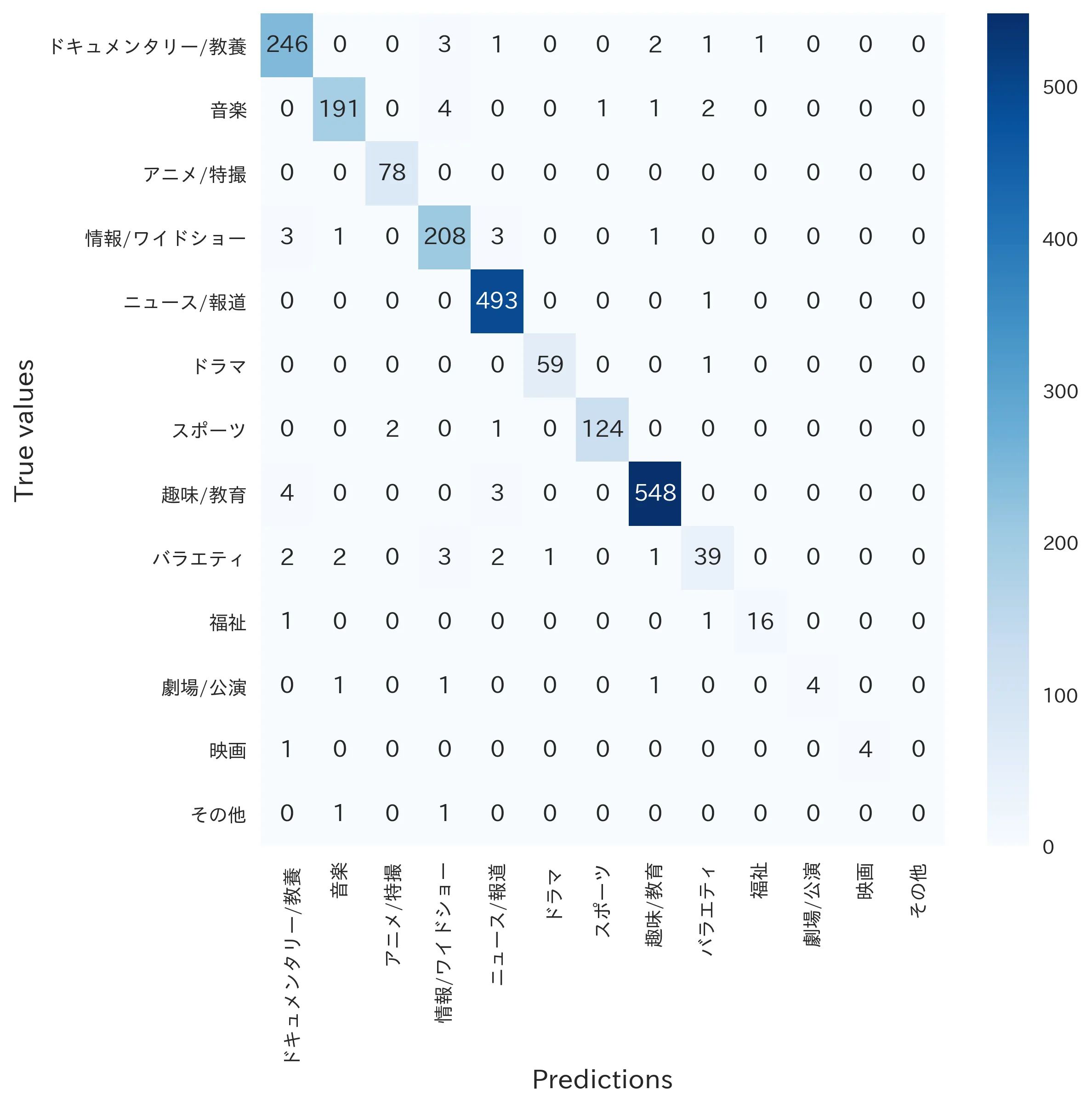
Looks pretty good right?
Conclusion
In this article, we have used a BERT pre-trained model and fine-tuned it for multi-class text classification for classifying Japanese TV and radio shows into multiple genres with 97% accuracy.
One trend I observed was that as the training data became larger, the accuracy was also increasing. 2 weeks of data was producing 94% accuracy while 1 month of data was able to produce 97% accuracy. I expect that this model can achieve near-perfect prediction accuracy as more data is collected. The next step for this model would be predicting multiple genres per show which would make this problem a multi-class multi-label problem.
Let me know if you have any questions/ feedback at danyelkoca@gmail.com. You can find the source code and the dataset below:
Happy hacking!
Leave comment
Comments
There are no comments at the moment.
Check out other works

2024/06/03
Kango: Guess The Kanji

2024/07/24
Lingo: Guess The Word

2024/04/29
Druggio

2024/01/28
Tetris

2022/04/29
Moving Object Detection

2022/03/15
Temperature Forecast

2022/02/09
House Price Prediction
2021/12/01
Japan Drug Database

2021/09/01
Travel Demand Prediction