Japan Drug Database
Published: December 1, 2021
In my previous job, I was finding myself doing a lot of desk research about drugs in Japan. For example, when we started a new project about a drug, it was common procedure for me to find the type of this drug, the diseases that the drug is indicated for (indications), the action mechanism, other drugs in the same field, the price of it, etc.
However, this becomes quite tedious when you are working with a drug with multiple indications. For example, some cancer drugs treat 10+ different cancer types. For this reason, finding the competitor landscape for each indication and the respective prices & manufacturers of each of these competitor drugs becomes a nightmare.
For this reason, I have decided to create a database of drugs in Japan. The main information I needed to collect for each of these drugs was:
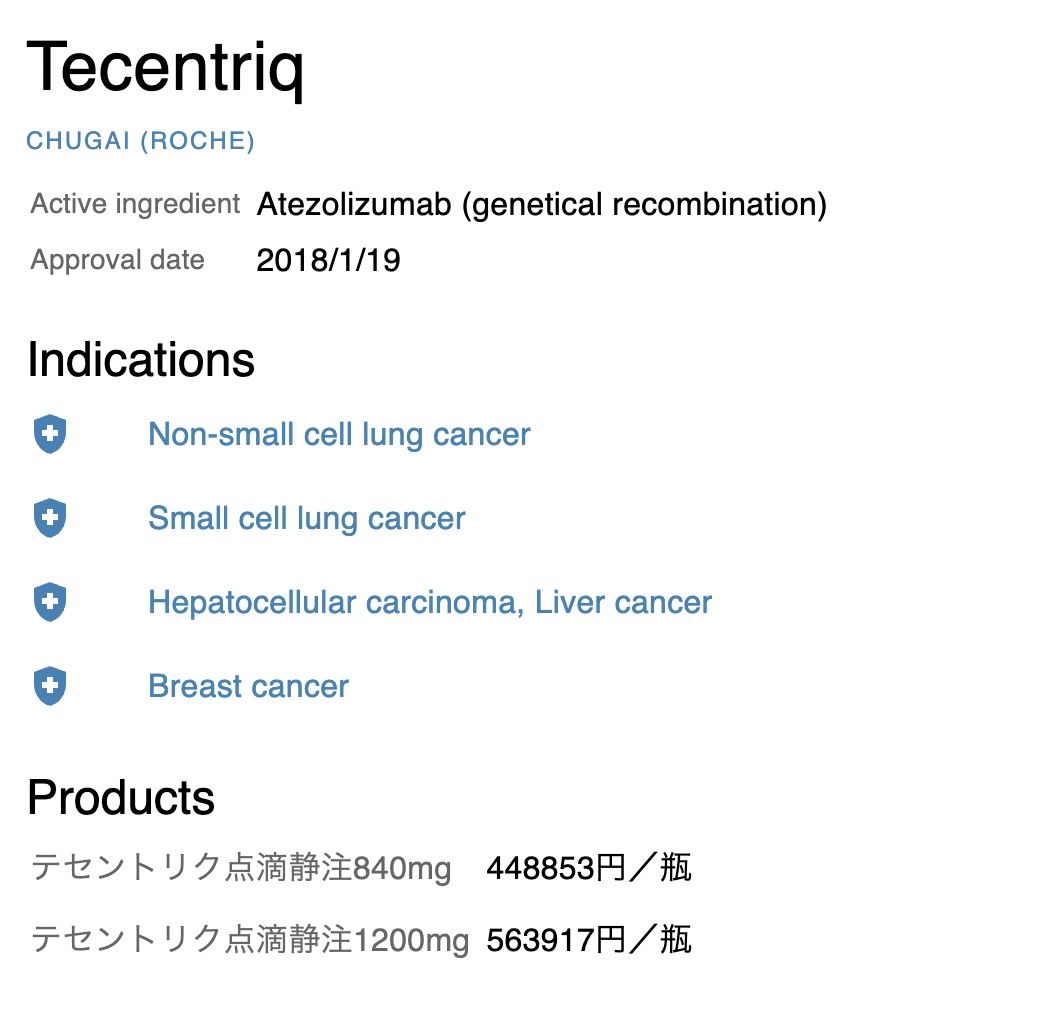
- Name of the drug
- Manufacturer
- Active ingredient
- Approval date
- Indications
- Products (ml / price)
And the idea was that, by clicking on an indication, you could see all drugs that are indicated for that disease. This would make it really easy to find competitors of a certain drug for a certain indication.
Moreover, you could look at all the drugs of a manufacturer (E.g. Pfizer) and see their whole portfolio.
Finally you would get a sweeping view of all indications of a drug, and the products of that drug because some drugs have several regimes (Pill, vaccine, different dossages, etc.)
Data collection
The data is mainly collected from KEGG: Kyoto Encyclopedia of Genes and Genomes. They are doing the heavy-lifting here as they curate all the necessary information, and what we need to do is to get that information, re-organize it across indications and manufacturers and make it easy to search by users.
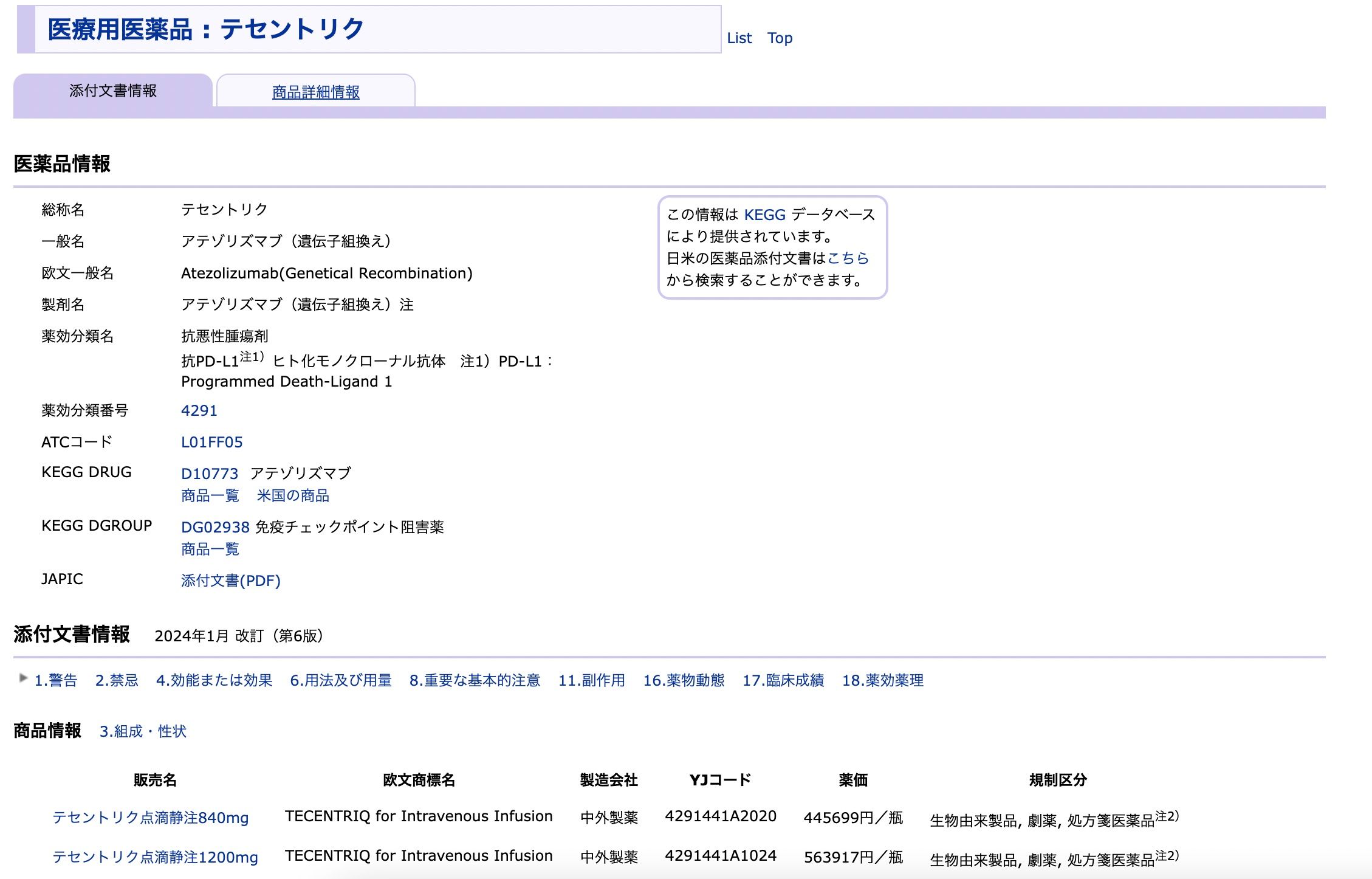
Data processing
Once the data is collected from KEGG, we need to do some processing which includes, removing old manufacturers and updating with their most current version, organizing data into English and Japanese, representing companies and diseases through IDs, in order to conduct exact search on them. The organized data looks like below:
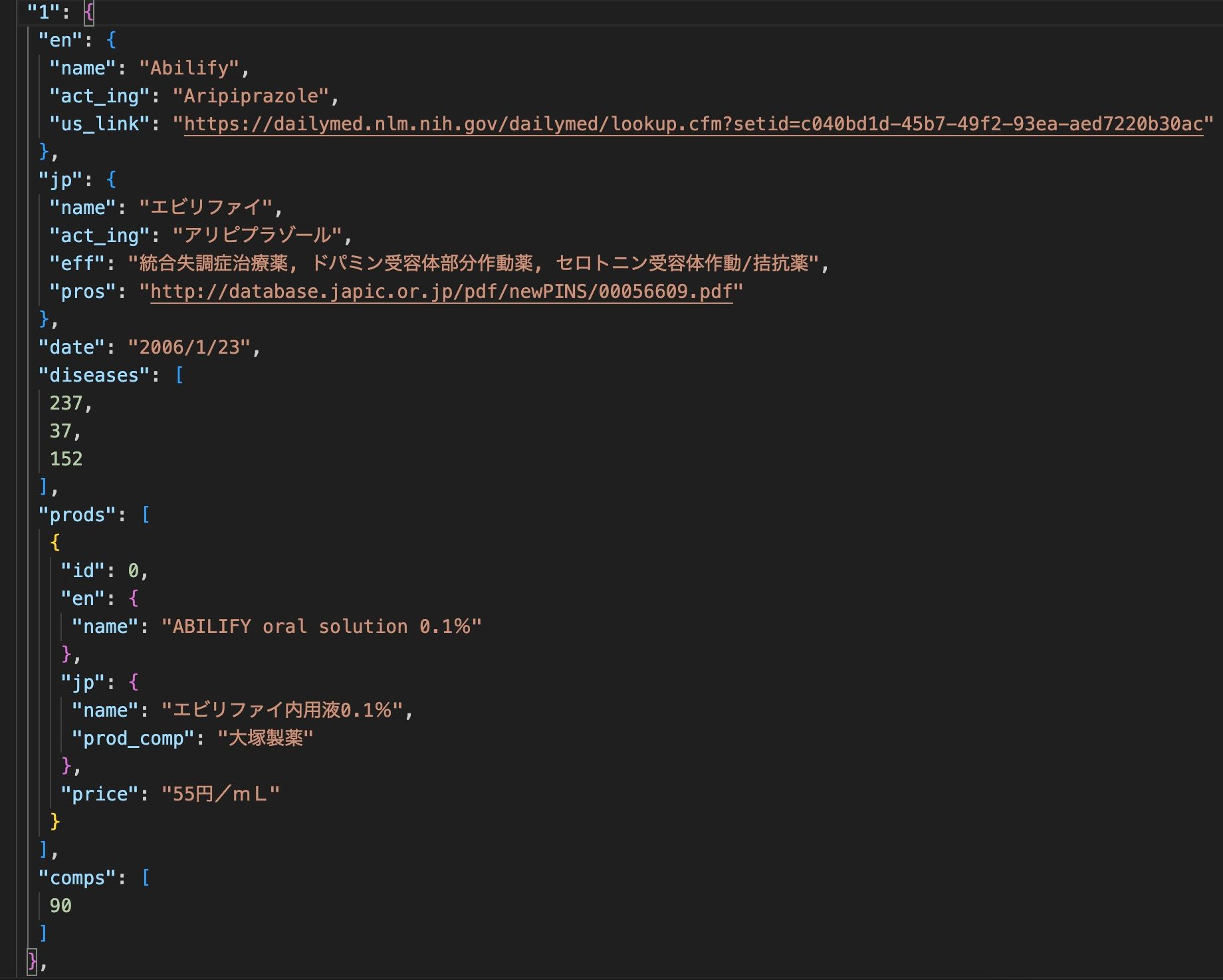
Above data structure is created for each drug and finally we have a database of drugs that are approved in Japan.
Serving the data
The most difficult part of this project (like most of data science projects) was to get the data in shape. Once we have the organized data, we now need to build a front/ back end to serve this data to users.
For this, we use NEXT.JS to build a Single-page-app to create an interface that lets the user search among drugs, competitors, indications and view results:
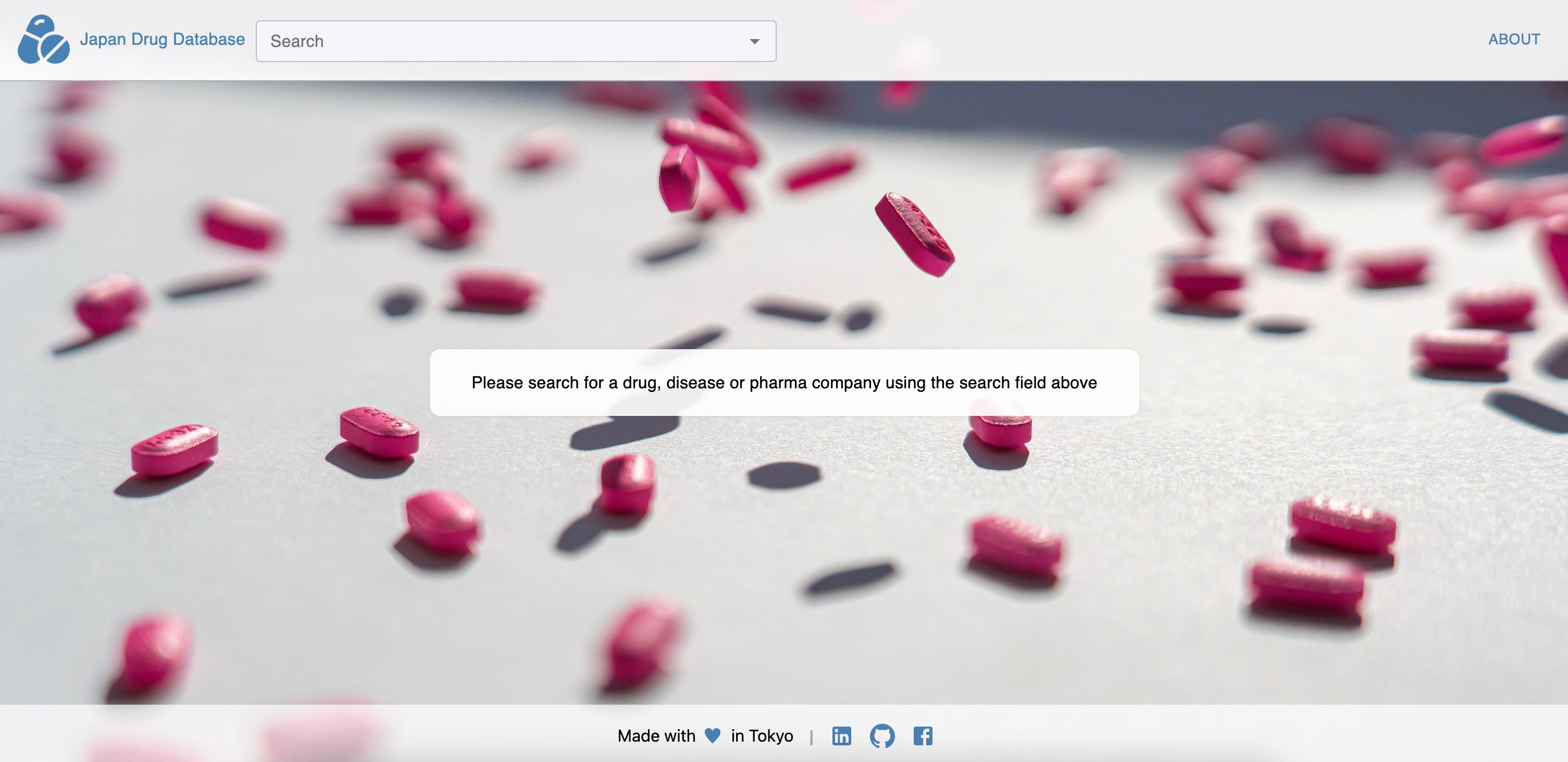
Conclusion
In this article, we saw how to create a database of drugs approved in Japan and build an interface to let users explore this data.
I call this project Japan Drug Database. You can find the link to the search engine here.
Let me knpow if you have any questions about the data & building the interface.
Happy hacking!
Leave comment
Comments
Check out other works

2025/10/12
Kumamap: Bear Incident Tracker

2025/07/07
YOLO Object Detection

2024/06/03
Kango: Guess The Kanji

2024/07/24
Lingo: Guess The Word

2024/04/29
Druggio

2024/01/28
Tetris

2022/04/29
Moving Object Detection

2022/03/15
Temperature Forecast

2022/02/09
House Price Prediction

2021/09/20
Japanese Text Classification

2021/09/01
Travel Demand Prediction