Most Commonly Used 3,000 Kanjis in Japanese
Published: June 7, 2024

Background
Recently, I was working on a game called Kango and I needed a list of most commonly used Kanjis in Japanese together with examples of words they are used in.
By the way, please give this game a try as it is quite fun to play, and it helps you improve your Kanjis. It is a great prep for JLPT.

I had studied Kanji from a book called 日本語学習のための よく使う順 漢字 2200 and as the name suggests, this book had most commonly used 2,200 kanjis together with examples of words that the kanji is used in.

I thought whether the authors made the kanjis used in this book open source. But no!
And there was no source on the web which collated the most commonly used Kanjis. So I decided to create one for the game.
Method
First of all, we download a list of most commonly used Japanese words from Matsushita Language Learning Lab's website. I also want to take this opportunity to thanks Prof. Matsushita and his lab as this list wouldn't be possible if they did not compile their list.
You can download the list of most commonly used words (VDRJ_Ver1_1_Research_Top60894.xlsx) by clicking here.
After downloading the data, run below code to get the most commonly used Kanjis:
## Code to generate MOST COMMONLY USED 3000 KANJIS
# Import needed libraries
import pandas as pd
import json
# Read data from the appropriate sheet
orig_df = pd.read_excel(
"data/VDRJ_Ver1_1_Research_Top60894.xlsx",
sheet_name="重要度順語彙リスト60894語",
)
# Function that detects whether a word includes a kanji
def kanji_detector(word):
kanji = False
non_jp_char = False
for char in word:
if (
"\u4e00" <= char <= "\u9faf"
or "\u3400" <= char <= "\u4dbf"
or "\uf900" <= char <= "\ufaff"
):
kanji = True
if (
not ("\u4e00" <= char <= "\u9faf")
and not ("\u3400" <= char <= "\u4dbf")
and not ("\uf900" <= char <= "\ufaff")
and not ("\u3040" <= char <= "\u30ff")
):
non_jp_char = True
return kanji and not (non_jp_char)
# Get the relevant column
df = (
orig_df[["見出し語彙素\nLexeme"]]
.astype(str)
.rename(columns={"見出し語彙素\nLexeme": "word"})
)
# Get words that are at least 2 character long and includes a kanji
df = df[df["word"].str.len() > 1]
df["kanji"] = df["word"].apply(kanji_detector)
df = df[df["kanji"]].drop("kanji", axis=1).reset_index(drop=True)
# Loop through the data to calculate the prevalance score of each Kanji
kanjis = {}
for index, word in enumerate(df["word"].to_list()):
for char in word:
if "\u4e00" <= char <= "\u9faf" or "\u3400" <= char <= "\u4dbf":
if char in kanjis:
kanjis[char]["count"] += 1
# Prevalence score is calculated as the inverse of commonness of a word
# If a word is common, it will contribute higher to the rank of Kanji
kanjis[char]["score"] += 1 / (index + 1)
if word not in [i["word"] for i in kanjis[char]["words"]]:
## Importance shows how commonly used that word is, lower the better
kanjis[char]["words"].append({"word": word, "importance": index})
else:
kanjis[char] = {
"count": 1,
"score": 1 / (index + 1),
"words": [{"word": word, "importance": index}],
}
# Sort kanjis based on their prevalence
kanjis_list = sorted(
[{"kanji": i, **kanjis[i]} for i in kanjis], key=lambda x: x["score"], reverse=True
)
# Get kanjis only if they are used in at least 3 words
kanjis_list = [i for i in kanjis_list if len(i["words"]) > 3]
# Remove some ambiguous kanji that are not really commonly used
unwanted_kanjis = [
"其",
"御",
"為",
"此",
"鱻",
"詞",
"掛",
"遣",
"又",
]
kanjis_list = [i for i in kanjis_list if i["kanji"] not in unwanted_kanjis]
# Exclude some more kanjis that include an ambiguous kanji
for i in kanjis_list:
i["words"] = [j for j in i["words"] if "鱻" not in j["word"]]
# Check a snapshot of results
for index, i in enumerate(kanjis_list[:100]):
print(f'{index}.{i["kanji"]}', end=" ")
# Save the top 3000 kanjis
with open("danyel_koca_most_common_3000_kanjis.json", "w") as f:
json.dump(kanjis_list[:3000], f, ensure_ascii=False)Result
The resulting list of 3000 most commonly used Kanjis look like below.
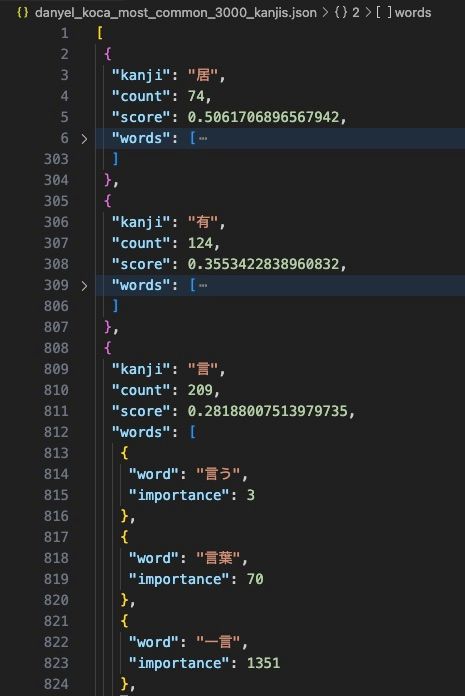
count shows how many word that Kanji appears in. But since the commonnness of a word influence the Kanji's importance, you see that Kanjis which are used less than others may appear on top.
score shows the prevalence of the Kanji. Higher the score, more prevalent that Kanji is.
importance shows the use frequency of a word. Lower the number, more frequently used that word is.
Conclusion
In this post, we have created a list of most commonly used 3000 Kanjis in Japanese. Hope this list will prove useful for people. Go out there and create something amazing with this.
You can download the List of Most Commonly Used 3000 Kanjis.
Fint the Github Repository for raw data, code, and resulting list.
Happy hacking!
Leave comment
Comments
Check out other blog posts

2026/03/24
My Claude Code Settings: Maximum Output Without Babysitting

2025/07/07
Q-Learning: Interactive Reinforcement Learning Foundation

2025/07/06
Optimization Algorithms: SGD, Momentum, and Adam

2025/07/05
Building a Japanese BPE Tokenizer: From Characters to Subwords

2024/06/19
Create A Simple and Dynamic Tooltip With Svelte and JavaScript
2024/06/17
Create an Interactive Map of Tokyo with JavaScript

2024/06/14
How to Easily Fix Japanese Character Issue in Matplotlib

2024/06/13
Book Review | Talking to Strangers: What We Should Know about the People We Don't Know by Malcolm Gladwell

2024/06/07
Replace With Regex Using VSCode

2024/06/06
Do Not Use Readable Store in Svelte

2024/06/05
Increase Website Load Speed by Compressing Data with Gzip and Pako

2024/05/31
Find the Word the Mouse is Pointing to on a Webpage with JavaScript

2024/05/29
Create an Interactive Map with Svelte using SVG

2024/05/28
Book Review | Originals: How Non-Conformists Move the World by Adam Grant & Sheryl Sandberg

2024/05/27
How to Algorithmically Solve Sudoku Using Javascript

2024/05/26
How I Increased Traffic to my Website by 10x in a Month

2024/05/24
Life is Like Cycling

2024/05/19
Generate a Complete Sudoku Grid with Backtracking Algorithm in JavaScript

2024/05/16
Why Tailwind is Amazing and How It Makes Web Dev a Breeze

2024/05/15
Generate Sitemap Automatically with Git Hooks Using Python

2024/05/14
Book Review | Range: Why Generalists Triumph in a Specialized World by David Epstein

2024/05/13
What is Svelte and SvelteKit?

2024/05/12
Internationalization with SvelteKit (Multiple Language Support)

2024/05/11
Reduce Svelte Deploy Time With Caching

2024/05/10
Lazy Load Content With Svelte and Intersection Oberver

2024/05/10
Find the Optimal Stock Portfolio with a Genetic Algorithm

2024/05/09
Convert ShapeFile To SVG With Python

2024/05/08
Reactivity In Svelte: Variables, Binding, and Key Function

2024/05/07
Book Review | The Art Of War by Sun Tzu

2024/05/06
Specialists Are Dead. Long Live Generalists!

2024/05/03
Analyze Voter Behavior in Turkish Elections with Python

2024/05/01
Create Turkish Voter Profile Database With Web Scraping

2024/04/30
Make Infinite Scroll With Svelte and Tailwind

2024/04/29
How I Reached Japanese Proficiency In Under A Year

2024/04/25
Use-ready Website Template With Svelte and Tailwind

2024/01/29
Lazy Engineers Make Lousy Products

2024/01/28
On Greatness
2024/01/28
Converting PDF to PNG on a MacBook

2023/12/31
Recapping 2023: Compilation of 24 books read

2023/12/30
Create a Photo Collage with Python PIL

2024/01/09
Detect Device & Browser of Visitors to Your Website

2024/01/19
Anatomy of a ChatGPT Response