日本語で最もよく使われる3000字の漢字
出版日: 2024年6月7日

背景
最近、私はKangoというゲームに取り組んでいて、日本語で最もよく使われる漢字のリストとその漢字が使用されている単語の例が必要でした。
ちなみに、このゲームを試してみてください。とても楽しく、漢字の習得にも役立ちます。JLPTの準備にも最適です。

私は日本語学習のための よく使う順 漢字 2200という本で漢字を勉強しました。この本には最もよく使われる2200の漢字と、その漢字が使われている単語の例が載っていました。

この本の著者がこの漢字をオープンソースにしているかどうかを考えました。しかし、そうではありませんでした。
そして、ウェブ上には最もよく使われる漢字をまとめたソースがありませんでした。そこで、私はゲーム用にリストを作成することにしました。
方法
まず最初に、松下言語学習研究所のウェブサイトから最もよく使われる日本語の単語リストをダウンロードします。このリストをコンパイルしてくださった松下教授と彼の研究室に感謝の意を表したいと思います。
最もよく使われる単語のリスト(VDRJ_Ver1_1_Research_Top60894.xlsx)はこちらからダウンロードできます。
データをダウンロードした後、以下のコードを実行して最もよく使われる漢字を取得します:
## Code to generate MOST COMMONLY USED 3000 KANJIS
# Import needed libraries
import pandas as pd
import json
# Read data from the appropriate sheet
orig_df = pd.read_excel(
"data/VDRJ_Ver1_1_Research_Top60894.xlsx",
sheet_name="重要度順語彙リスト60894語",
)
# Function that detects whether a word includes a kanji
def kanji_detector(word):
kanji = False
non_jp_char = False
for char in word:
if (
"\u4e00" <= char <= "\u9faf"
or "\u3400" <= char <= "\u4dbf"
or "\uf900" <= char <= "\ufaff"
):
kanji = True
if (
not ("\u4e00" <= char <= "\u9faf")
and not ("\u3400" <= char <= "\u4dbf")
and not ("\uf900" <= char <= "\ufaff")
and not ("\u3040" <= char <= "\u30ff")
):
non_jp_char = True
return kanji and not (non_jp_char)
# Get the relevant column
df = (
orig_df[["見出し語彙素\nLexeme"]]
.astype(str)
.rename(columns={"見出し語彙素\nLexeme": "word"})
)
# Get words that are at least 2 character long and includes a kanji
df = df[df["word"].str.len() > 1]
df["kanji"] = df["word"].apply(kanji_detector)
df = df[df["kanji"]].drop("kanji", axis=1).reset_index(drop=True)
# Loop through the data to calculate the prevalance score of each Kanji
kanjis = {}
for index, word in enumerate(df["word"].to_list()):
for char in word:
if "\u4e00" <= char <= "\u9faf" or "\u3400" <= char <= "\u4dbf":
if char in kanjis:
kanjis[char]["count"] += 1
# Prevalence score is calculated as the inverse of commonness of a word
# If a word is common, it will contribute higher to the rank of Kanji
kanjis[char]["score"] += 1 / (index + 1)
if word not in [i["word"] for i in kanjis[char]["words"]]:
## Importance shows how commonly used that word is, lower the better
kanjis[char]["words"].append({"word": word, "importance": index})
else:
kanjis[char] = {
"count": 1,
"score": 1 / (index + 1),
"words": [{"word": word, "importance": index}],
}
# Sort kanjis based on their prevalence
kanjis_list = sorted(
[{"kanji": i, **kanjis[i]} for i in kanjis], key=lambda x: x["score"], reverse=True
)
# Get kanjis only if they are used in at least 3 words
kanjis_list = [i for i in kanjis_list if len(i["words"]) > 3]
# Remove some ambiguous kanji that are not really commonly used
unwanted_kanjis = [
"其",
"御",
"為",
"此",
"鱻",
"詞",
"掛",
"遣",
"又",
]
kanjis_list = [i for i in kanjis_list if i["kanji"] not in unwanted_kanjis]
# Exclude some more kanjis that include an ambiguous kanji
for i in kanjis_list:
i["words"] = [j for j in i["words"] if "鱻" not in j["word"]]
# Check a snapshot of results
for index, i in enumerate(kanjis_list[:100]):
print(f'{index}.{i["kanji"]}', end=" ")
# Save the top 3000 kanjis
with open("danyel_koca_most_common_3000_kanjis.json", "w") as f:
json.dump(kanjis_list[:3000], f, ensure_ascii=False)結果
結果として得られた最もよく使われる3000の漢字のリストは以下の通りです。
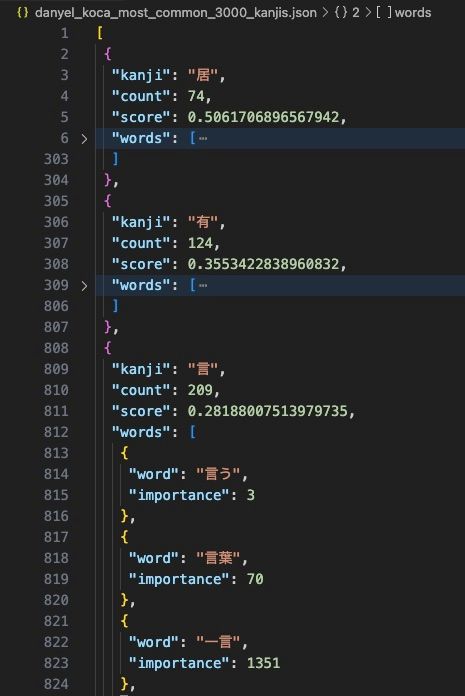
countはその漢字がどれだけの単語に現れるかを示します。しかし、単語の共通度が漢字の重要性に影響を与えるため、他の漢字よりも少ない使用頻度の漢字が上位に表示されることがあります。
scoreはその漢字の普及度を示します。スコアが高いほど、その漢字はより普及しています。
importanceは単語の使用頻度を示します。数字が低いほど、その単語はより頻繁に使用されます。
結論
この投稿では、日本語で最もよく使われる3000の漢字のリストを作成しました。このリストが人々にとって有用であることを願っています。素晴らしいものを作り出してください。
最もよく使われる3000の漢字リストをダウンロードできます。
生データ、処理コード、および結果はGithubリポジトリにあるます。
Happy Hacking!
このブログは英語からChatGPTによって翻訳されました。不明な点がある場合は、お問い合わせページからご連絡ください。
コメントを残す
コメント
現在コメントがありません。
その他のブログ
2024/06/19
SvelteとJavaScriptを使用してシンプルで動的なツールチップを作成する
2024/06/17
JavaScriptを用いて東京都のインタラクティブな地図を作成する

2024/06/14
Matplotlibで日本語文字化けを解決できる簡単な方法

2024/06/13
書評 | トーキング・トゥ・ストレンジャーズ 「よく知らない人」について私たちが知っておくべきこと by マルコム・グラッドウェル

2024/06/07
VSCodeでRegexを使用してReplaceする方法

2024/06/06
SvelteではReadable Storeを使用するな

2024/06/05
GzipとPakoでデータを圧縮してWebサイトのローディング速度を上げる方法

2024/05/31
JavaScriptを使用してWebページ上でマウスが指している単語を特定する

2024/05/29
SvelteとSVGを用いてインタラクティブな地図を作成する

2024/05/28
書評 | Originals 誰もが「人と違うこと」ができる時代 by アダム・グラント & シェリル・サンドバーグ
2024/05/27
Javascriptを使用して数独を解く方法
2024/05/26
ウェブサイトへのトラフィックを1か月で10倍に増やした方法

2024/05/24
人生はサイクリングに似ている

2024/05/19
JavaScriptでバックトラッキング・アルゴリズムを用いて完全な数独グリッドを生成する

2024/05/16
Tailwindが素晴らしい理由とWeb開発をいかに楽にするか

2024/05/15
PythonとGitフックを使用してサイトマップを自動的に生成する

2024/05/14
書評 | Range (レンジ) 知識の「幅」が最強の武器になる by デイビッド・エプスタイン

2024/05/13
SvelteとSvelteKitはなんですか?
2024/05/12
SvelteKitで国際化(多言語化)
2024/05/11
SvelteでCachingを用いてDeploy時間を短縮する方法

2024/05/10
SvelteとIntersection Oberverによるレイジーローディング

2024/05/10
遺伝的アルゴリズムで最適な株式ポートフォリオを作る方法
2024/05/09
Pythonを用いてShapeFileをSVGに変換できる方法

2024/05/08
Svelteの反応性:変数、バインディング、およびキー関数

2024/05/07
書評 | 孫子の兵法

2024/05/06
スペシャリストは終了。ゼネラリスト万歳!

2024/05/03
トルコ人の有権者の投票行動をPythonでの分析

2024/05/01
Seleniumを用いてトルコ投票データベースを作る方法

2024/04/30
SvelteとTailwindを使用してInfinite Scrollできる方法

2024/04/29
1年間以内で日本語を駆使できるようになるための方法
2024/04/25
SvelteとTailwindを用いたWebサイトテンプレート

2024/01/29
怠惰なエンジニアとひどいデザイン

2024/01/28
偉大さについて
2024/01/28
MacBook で PDF を PNG に変換する

2023/12/31
2023年振り返り:24冊の読んだ本のまとめ

2023/12/30
Python PILを使用して写真コラージュを作成する方法

2024/01/09
ウェブサイトの訪問者のデバイスとブラウザを検出する方法

2024/01/19
ChatGPT回答の解析