Japonca'da En Sık Kullanılan 3.000 Kanji
Yayın: 7 Haziran 2024

Arka Plan
Son zamanlarda, Kango adında bir oyun üzerinde çalışıyordum ve Japoncada en sık kullanılan Kanji karakterlerinin, bu karakterlerin kullanıldığı kelime örnekleriyle birlikte bir listesine ihtiyacım vardı.
Bu arada, lütfen bu oyunu deneyin çünkü oynaması oldukça eğlenceli ve Kanji karakterlerinizi geliştirmenize yardımcı oluyor. JLPT'ye hazırlık için harika bir oyun.

Kanji'yi 日本語学習のための よく使う順 漢字 2200 adında bir kitaptan öğrendim ve adından da anlaşılacağı gibi, bu kitapta en sık kullanılan 2.200 Kanji karakteri ve bu karakterlerin kullanıldığı kelimelerin örnekleri bulunuyordu.

Yazarların bu kitaptaki Kanji karakterlerini açık kaynak yapıp yapmadığını merak ettim. Ama hayır!
Ve web üzerinde en sık kullanılan Kanji karakterlerini derleyen bir kaynak yoktu. Bu yüzden oyun için bir liste oluşturmaya karar verdim.
Yöntem
İlk olarak, Matsushita Dil Öğrenme Laboratuvarı'nın web sitesinden en sık kullanılan Japonca kelimelerin listesini indiriyoruz. Bu listeyi derledikleri için Prof. Matsushita ve laboratuvarına teşekkür etmek istiyorum.
En sık kullanılan kelimelerin listesini (VDRJ_Ver1_1_Research_Top60894.xlsx) indirmek için buraya tıklayabilirsiniz.
Verileri indirdikten sonra, en sık kullanılan Kanji karakterlerini elde etmek için aşağıdaki kodu çalıştırın:
## Code to generate MOST COMMONLY USED 3000 KANJIS
# Import needed libraries
import pandas as pd
import json
# Read data from the appropriate sheet
orig_df = pd.read_excel(
"data/VDRJ_Ver1_1_Research_Top60894.xlsx",
sheet_name="重要度順語彙リスト60894語",
)
# Function that detects whether a word includes a kanji
def kanji_detector(word):
kanji = False
non_jp_char = False
for char in word:
if (
"\u4e00" <= char <= "\u9faf"
or "\u3400" <= char <= "\u4dbf"
or "\uf900" <= char <= "\ufaff"
):
kanji = True
if (
not ("\u4e00" <= char <= "\u9faf")
and not ("\u3400" <= char <= "\u4dbf")
and not ("\uf900" <= char <= "\ufaff")
and not ("\u3040" <= char <= "\u30ff")
):
non_jp_char = True
return kanji and not (non_jp_char)
# Get the relevant column
df = (
orig_df[["見出し語彙素\nLexeme"]]
.astype(str)
.rename(columns={"見出し語彙素\nLexeme": "word"})
)
# Get words that are at least 2 character long and includes a kanji
df = df[df["word"].str.len() > 1]
df["kanji"] = df["word"].apply(kanji_detector)
df = df[df["kanji"]].drop("kanji", axis=1).reset_index(drop=True)
# Loop through the data to calculate the prevalance score of each Kanji
kanjis = {}
for index, word in enumerate(df["word"].to_list()):
for char in word:
if "\u4e00" <= char <= "\u9faf" or "\u3400" <= char <= "\u4dbf":
if char in kanjis:
kanjis[char]["count"] += 1
# Prevalence score is calculated as the inverse of commonness of a word
# If a word is common, it will contribute higher to the rank of Kanji
kanjis[char]["score"] += 1 / (index + 1)
if word not in [i["word"] for i in kanjis[char]["words"]]:
## Importance shows how commonly used that word is, lower the better
kanjis[char]["words"].append({"word": word, "importance": index})
else:
kanjis[char] = {
"count": 1,
"score": 1 / (index + 1),
"words": [{"word": word, "importance": index}],
}
# Sort kanjis based on their prevalence
kanjis_list = sorted(
[{"kanji": i, **kanjis[i]} for i in kanjis], key=lambda x: x["score"], reverse=True
)
# Get kanjis only if they are used in at least 3 words
kanjis_list = [i for i in kanjis_list if len(i["words"]) > 3]
# Remove some ambiguous kanji that are not really commonly used
unwanted_kanjis = [
"其",
"御",
"為",
"此",
"鱻",
"詞",
"掛",
"遣",
"又",
]
kanjis_list = [i for i in kanjis_list if i["kanji"] not in unwanted_kanjis]
# Exclude some more kanjis that include an ambiguous kanji
for i in kanjis_list:
i["words"] = [j for j in i["words"] if "鱻" not in j["word"]]
# Check a snapshot of results
for index, i in enumerate(kanjis_list[:100]):
print(f'{index}.{i["kanji"]}', end=" ")
# Save the top 3000 kanjis
with open("danyel_koca_most_common_3000_kanjis.json", "w") as f:
json.dump(kanjis_list[:3000], f, ensure_ascii=False)Sonuç
Ortaya çıkan en sık kullanılan 3000 Kanji karakterinin listesi aşağıdaki gibidir.
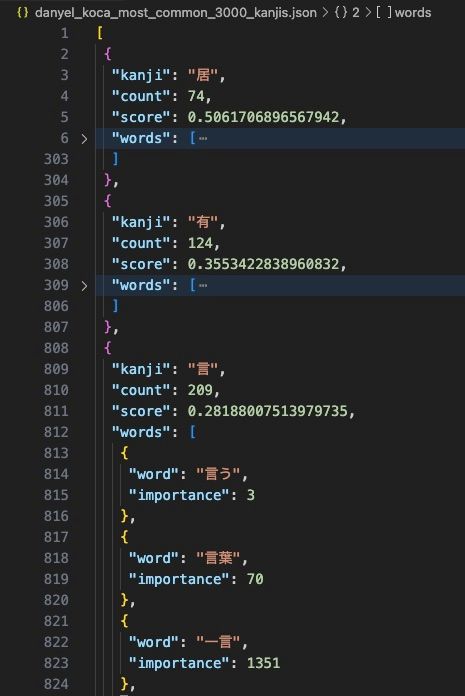
count Kanji'nin kaç kelimede göründüğünü gösterir. Ancak, bir kelimenin yaygınlığı Kanji'nin önemini etkilediğinden, diğerlerinden daha az kullanılan Kanji karakterlerinin üst sıralarda görünebilir.
score Kanji'nin yaygınlığını gösterir. Skor ne kadar yüksekse, Kanji o kadar yaygındır.
importance bir kelimenin kullanım sıklığını gösterir. Sayı ne kadar düşükse, o kelime o kadar sık kullanılır.
Sonuç
Bu yazıda, Japoncada en sık kullanılan 3000 Kanji karakterinin bir listesini oluşturduk. Bu listenin insanlar için faydalı olacağını umuyoruz. Gidin ve bununla harika bir şeyler yaratın.
En sık Kullanılan 3000 Kanji Karakteri Listesi'ni indirebilirsiniz.
Ham veriler, kod ve sonuç için Github Repo'sunu ziyaret edebilirsiniz.
Mutlu kodlamalar!
Bu blog İngilizce'den ChatGPT ile çevrilmiştir. Herhangi bir belirsizlik durumunda İletişim sayfasından bana ulaşabilirsiniz.
Yorum bırak
Yorumlar
Şuan yorum yok.
Diğer bloglara bak
2024/06/19
Svelte ve JavaScript ile Basit ve Dinamik Bir Tooltip Yaratma Yöntemi
2024/06/17
JavaScript ile Tokyo'nun İnteraktif Haritasını Oluşturun

2024/06/14
Matplotlib'de Japonca Karakter Sorununu Çözme Yöntemi

2024/06/13
Kitap İncelemesi | Ötekiyle Konuşmak by Malcolm Gladwell

2024/06/07
VSCode'da Regex Kullanarak Replace Yapma Yöntemi

2024/06/06
Svelte'de Readable Store Kullanmayın

2024/06/05
Dosyaları Gzip ve Pako ile Sıkıştırarak Web Sitesinin Yükleme Hızını Artırın

2024/05/31
Web Sayfasında Farenin Uzerinde Oldugu Kelimeyi JavaScript ile Bulun

2024/05/29
Svelte ve SVG ile Interaktif Harita Oluşturun

2024/05/28
Kitap İncelemesi | Geleneklere Uymayanlar Dünyayı Nasıl İleri Taşıyor? by Adam Grant & Sheryl Sandberg
2024/05/27
Javascript Kullanarak Sudoku Nasıl Çözülür?
2024/05/26
Web Siteme Gelen Trafiği Bir Ayda Nasıl 10 Kat Artırdım?

2024/05/24
Hayat Bisiklet Sürmek Gibidir

2024/05/19
JavaScript'te Backtracking Algoritması ile Tamamlanmış Sudoku Oluşturun

2024/05/16
Tailwind Neden Harikadır ve Web Geliştirmeyi Nasıl Kolay Hale Getirir?

2024/05/15
Python ve Git Hooks ile Otomatik Olarak Site Haritası Oluşturma

2024/05/14
Kitap İncelemesi | Çok Yönlü - Başarı İçin Neden Çok Şeyle İlgilenmeliyiz? by David Epstein

2024/05/13
Svelte ve SvelteKit nedir?
2024/05/12
SvelteKit ile Internationalization (Çoklu Dil Desteği)
2024/05/11
Svelte'de Caching ile Deploy Süresini Azaltın

2024/05/10
Svelte ve Intersection Oberver ile Lazy-Load

2024/05/10
Genetik Algoritma İle Hisse Senedi Portföyü Optimizasyonu
2024/05/09
ShapeFile Formatini SVG Formatina Degistirme Yontemi

2024/05/08
Svelte'de Reaktivite: Variables, Binding, ve Key Fonksiyonu

2024/05/07
Kitap İncelemesi | Savaş Sanatı - Sun Tzu

2024/05/06
Specialistlik Bitti. Yaşasın Generalistlik!

2024/05/03
2018 Milletvekili Seçimlerinde Yaşa Göre Parti Eğilimi

2024/05/01
Python Selenium Ile Secmen Veritabani Olusturma

2024/04/30
Svelte ve Tailwind Ile Infinite Scroll Yapma Yontemi

2024/04/29
1 Yıl İçerisinde Japonca Konuşabilmek
2024/04/25
Svelte ve Tailwind ile Kullanıma Hazır Web Sitesi Şablonu

2024/01/29
Tembel Muhendisler Kotu Urunler Yapar

2024/01/28
Mukemmellik Uzerine
2024/01/28
MacBook'ta PDF'i PNG'ye Cevirme Yontemi

2023/12/31
2023'u Kapatiyoruz: Bu Yil Okunan 24 Kitap

2023/12/30
Python PIL Kullarak Foto Kolaji Yapma Yontemi

2024/01/09
Site Ziyaretcilerinin Alet ve Tarayicilarini Tespit Etme Yontemi

2024/01/19
ChatGPT Cevap Anatomisi